음성 변환 모델이 어정쩡한 목소리를 내는 이유
음성 변환 데모를 들으면 늘 두 화자가 섞인 듯한 묘한 톤이 나오는데, 이게 단순한 학습 부족이 아니라 timbre leakage라는 구조적 문제임을 정리. Seed-VC라는 모델이 이걸 어떤 발상으로 우회하는지, 백엔드 입장에선 어떤 한계가 깔려있는지 솔직히 적었음.
음성 변환(voice conversion) — 한 사람의 목소리를 다른 사람 목소리로 바꾸는 기술임. 말의 내용은 그대로 두고 톤만 갈아끼우는 건데, AI 더빙이나 가상 유튜버, 개인화 TTS 같은 데서 자주 보이는 응용. 근데 데모를 들어볼 때마다 묘하게 거슬리는 게 있었다. 분명 A 화자 목소리로 시작했고 B로 바뀐다고 했는데, 결과물이 A도 아니고 B도 아닌 어떤 중간 지점에서 멈춰있는 느낌.
이게 그냥 모델이 덜 학습돼서 그런 줄 알았는데, zero-shot 음성 변환 쪽 흐름을 따라가보니 의외로 구조적인 문제더라고요.
본문에 자주 나오는 용어 짧게 정리.
- zero-shot 음성 변환: 새 화자마다 모델을 다시 학습시키지 않고, 짧은 reference 오디오 한 토막만 주면 그 사람 목소리로 변환해주는 방식
- timbre: 사람마다 다른 목소리 고유의 색깔. 흔히 "음색"으로 번역됨
- mel spectrogram: 음성 신호를 시간-주파수 평면에 펼쳐 그린 이미지 같은 표현. 음성 모델이 보통 직접 다루는 입력
- diffusion: 노이즈에서 점진적으로 데이터를 만들어가는 생성 방식. 이미지에서 출발했지만 음성에도 잘 들어맞는다고 함

콘텐츠와 화자를 분리한다는 환상
음성 변환의 기본 아이디어는 단순함. 한 음성에서 "무엇을 말했는지(콘텐츠)"와 "누가 말했는지(화자)"를 분리한 뒤, 콘텐츠는 그대로 두고 화자만 다른 사람 걸로 바꿔치기. 깔끔하고 직관적이라 듣기엔 그럴듯한데, 진짜로 분리가 되느냐가 문제.
콘텐츠 추출엔 wav2vec이나 HuBERT 같은 self-supervised 음성 모델을 많이 쓰는데, 이 표현이 화자 정보로부터 진짜 깨끗하게 분리되어 있냐고 하면 그건 또 별개 얘기. 미묘하게 원래 화자의 흔적이 남아있어서, 거기다 타깃 화자 정보를 더하면 두 명이 섞인 결과물이 나옴. 이게 "어정쩡한 목소리"의 정체이고, 영어권에서는 이걸 timbre leakage라고 부른다.
한 줄짜리 임베딩으로 사람 목소리를 표현한다는 것
또 하나의 문제. 타깃 화자를 어떻게 표현할 거냐. 대부분의 시스템이 사람 목소리를 단일 임베딩 벡터 하나로 압축함. 학습 때 본 화자라면 이게 그럭저럭 통하는데, zero-shot 상황에선 얘기가 달라짐.
말투 리듬, 호흡 길이, 강세 위치 같은 게 다 한 벡터에 압축되니까 결과물이 평평해짐. 비슷하긴 한데 그 사람인지는 아리송한 톤이 나옴. 솔직히 이건 어떤 architecture를 가져와도 어느 정도 깔리는 한계라고 본다.
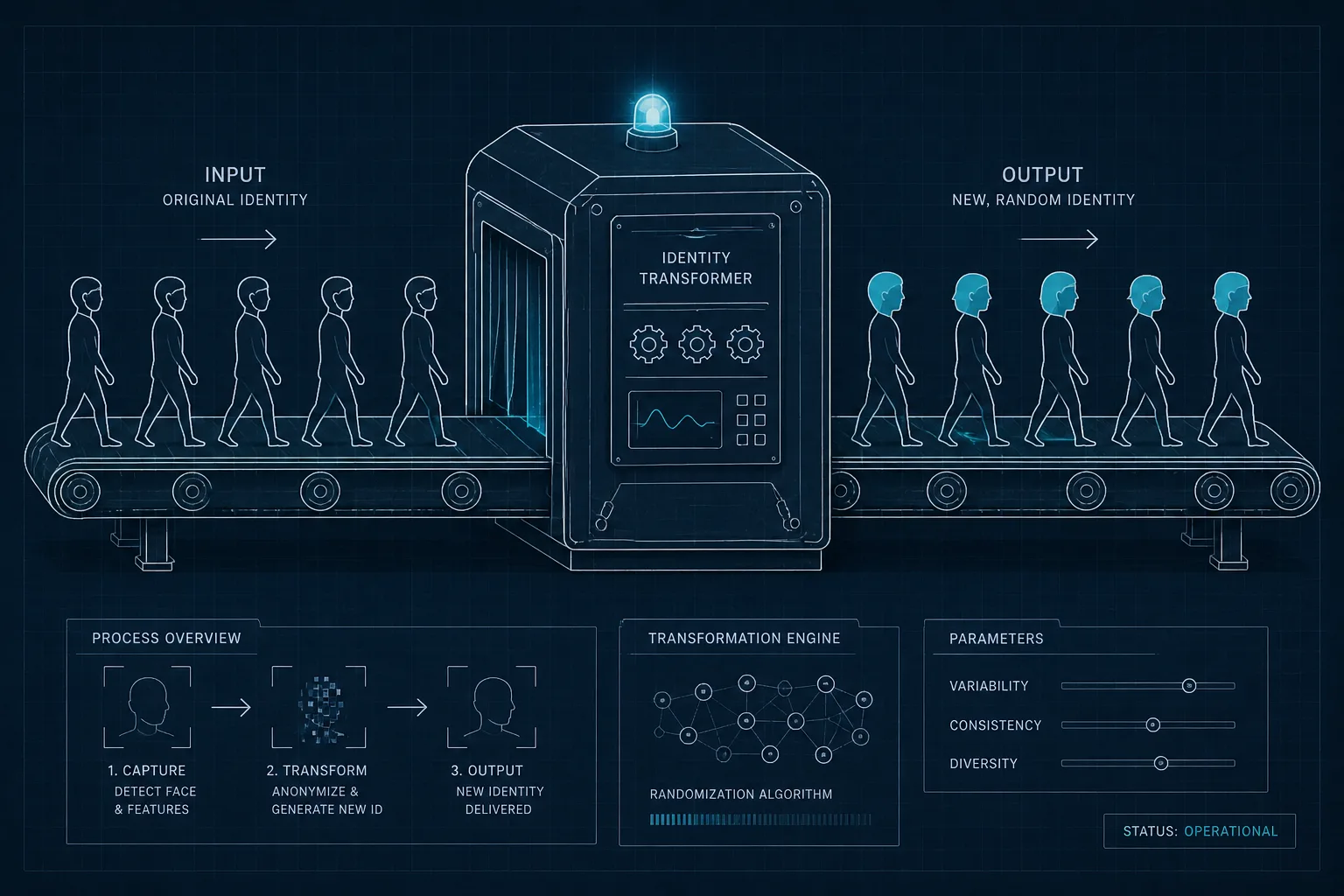
학습할 땐 같은 사람, 추론할 땐 다른 사람
세 번째 문제는 좀 더 본질적인데, 대부분 음성 변환 모델은 학습할 때 같은 화자의 음성을 재구성하는 식으로 훈련되거든요.
content (A) + timbre (A) → speech (A)근데 inference에서 우리가 실제로 시키는 건:
content (A) + timbre (B) → speech (B)학습한 적 없는 작업을 시키는 거임. 모델 입장에선 한 번도 안 해본 일을 잘하라는 요구.
Seed-VC가 푸는 방식 — timbre shifter라는 트릭
요즘 zero-shot 음성 변환 쪽에서 자주 거론되는 모델 중 하나가 Seed-VC인데, 이 세 문제를 흥미로운 트릭으로 풀어냄.
핵심은 timbre shifter. 원본 음성에서 바로 콘텐츠를 추출하지 않고, 일단 화자를 무작위 다른 사람으로 한 번 바꿔치기한 뒤에 콘텐츠를 추출함.
원본 음성 (A)
↓
Timbre Shifter — A를 무작위 화자 R로 변환
↓
이 변환된 음성에서 콘텐츠 추출
↓
+ 타깃 화자 정보
↓
출력이게 왜 통하냐. 기존 방식의 문제는 콘텐츠 안에 원본 화자 흔적이 남는 거였는데, Seed-VC는 그걸 완전히 제거하려는 노력 자체를 포기함. 대신 매번 다른 임의 화자 흔적이 섞이도록 만들어버린다.
학습 과정에서 같은 입력 A가 매번 다른 R로 변환되니까, 모델 입장에선 콘텐츠 안에 들어있는 화자 정보가 신뢰할 수 없는 노이즈가 됨. loss를 줄이려면 그 정보를 무시할 수밖에 없고, 결과적으로 모델은 자연스럽게 "무슨 말을 했는지"에만 집중하게 됨.
화자 정보를 깔끔히 지우는 대신 일부러 더럽혀서 쓸모없게 만드는 발상. 이거 좀 영리한 우회임.
학습 자체를 inference에 가깝게
timbre shifter가 깔리면 부수효과가 하나 더 생김. 학습할 때부터 자연스럽게 mismatched speaker 환경이 만들어져요.
shifted speech (A → R) + timbre (A) → speech (A)학습할 때 이미 다른 화자에서 다른 화자로 변환하는 걸 학습하는 셈이니까, inference에서 새 화자가 나와도 같은 task가 되는 거지. training-inference gap이 자연스럽게 사라짐. 한 트릭으로 두 가지 문제를 동시에 푸는 셈인데, 이런 게 디자인이 잘 된 모델 같다.
Diffusion Transformer + Flow Matching
생성부는 diffusion transformer를 씀. U자형 transformer 백본에 RoPE를 더해서 시간 구조를 잡고, classifier-free guidance를 같이 학습. 음성처럼 시간 축이 중요한 데이터에선 attention 기반 모델이 잘 들어맞는다는 게 이쪽 통설.
학습 전략은 flow matching인데, 노이즈에서 깨끗한 데이터로 가는 "방향(velocity)"을 직접 예측하게 만드는 방식. 일반적인 score-based diffusion보다 학습이 안정적이고 추론도 빠르다는 보고가 있음. 안 돌려봐서 정확한 차이는 모르겠는데, 적어도 코드 복잡도는 score matching보다 단순한 편이라고 함.

직접 돌려보지 않고 코드/논문 정도만 본 입장에서의 한계
여기까지 보면 그럴듯한데, 한 발 떨어져서 보면 의문도 있음.
첫째, 의존하는 외부 모델이 많다. timbre shifter로 OpenVoice를 그대로 가져다 쓰고, 화자 임베딩은 CAM++, 콘텐츠 추출은 Wav2Vec2, vocoder는 HiFi-GAN. 즉 "Seed-VC가 잘 돈다"는 명제는 사실상 "이 네 가지가 모두 충분히 잘 돈다"의 합성. 한국어처럼 학습 데이터에서 비중이 작은 언어에선 어느 한 군데가 약해질 가능성이 충분히 있다고 본다.
둘째, 학습 데이터가 LibriTTS 영어 단일. 다국어/한국어에서 어떻게 작동할지는 별도로 검증해야 됨. zero-shot이라고 해도, 학습 데이터 분포에서 너무 멀어진 화자에선 결국 품질이 떨어진다는 게 음성 합성 쪽 통설이기도 하고.
셋째, "어정쩡한 목소리"가 정말로 사라졌는지는 듣는 사람마다 평가가 갈림. timbre leakage를 줄이는 건 맞아 보이지만, 단일 임베딩 벡터로 화자 표현하는 두 번째 문제는 여전히 깔려있음. 후기들 보면 평탄함은 어느 정도 줄었는데 완전히 해결된 건 아닌 듯.
좀 다른 얘기 — 음성 모델이 진입 장벽이 높게 느껴지는 이유
여담인데, 백엔드 위주로 일하다 보면 음성 쪽 모델은 진입 장벽이 묘하게 높게 느껴짐. 이미지는 픽셀이고 텍스트는 토큰이라 직관적인데, 음성은 일단 "mel spectrogram이 뭐냐"부터 시작해서 시간 해상도, hop length, sample rate 같은 자질구레한 게 모델 위에 한 겹 더 깔려있음. 같은 transformer 구조라도 input/output 다듬는 부분이 어쩐지 더 까다롭게 보인다.

정리
음성 변환의 핵심 어려움은 "분리할 수 없는 걸 분리하려는 데서" 옴. Seed-VC의 트릭은 그 사실을 인정하고 우회한 거고, 발상 자체는 깔끔하다고 본다. 근데 zero-shot 음성 변환이 진짜 production grade로 쓸만하냐는 별개 문제. 데모 좋아 보인다고 사이드 프로젝트에 그대로 끼워넣으면 한국어 화자에서 다시 막힐 가능성이 충분히 있음.
다음 글에선 OpenVoice 자체 구조를 한번 풀어볼 생각. timbre shifter로 쓰이고 있는데, 정작 이 모델이 어떻게 만들어졌는지가 더 궁금해서.

음성 모델은 결과물을 귀로 듣고 평가해야 한다는 점에서 다른 분야랑 결이 좀 다른데, 그래서 더 흥미로움. 직접 돌려봐야 진짜 평가가 나오는 분야임.
댓글
NEXT_PUBLIC_GISCUS_*환경변수 구성 필요)