Open-vocabulary 모델이라며, 결국 fine-tuning이 표준이 된 이유
YOLO-World 같은 open-vocabulary 객체 탐지 모델의 셀링 포인트는 zero-shot 검출인데, 정작 영어권 튜토리얼은 절반 이상이 "fine-tuning하는 법"으로 끝나는 패러독스를 정리. 사실 이 둘은 모순이 아니라 워크플로의 단계가 다른 거고, 한국어 라벨을 쓰는 환경에선 fine-tuning이 더 일찍 필요해진다는 추가 변수까지 짚었음.
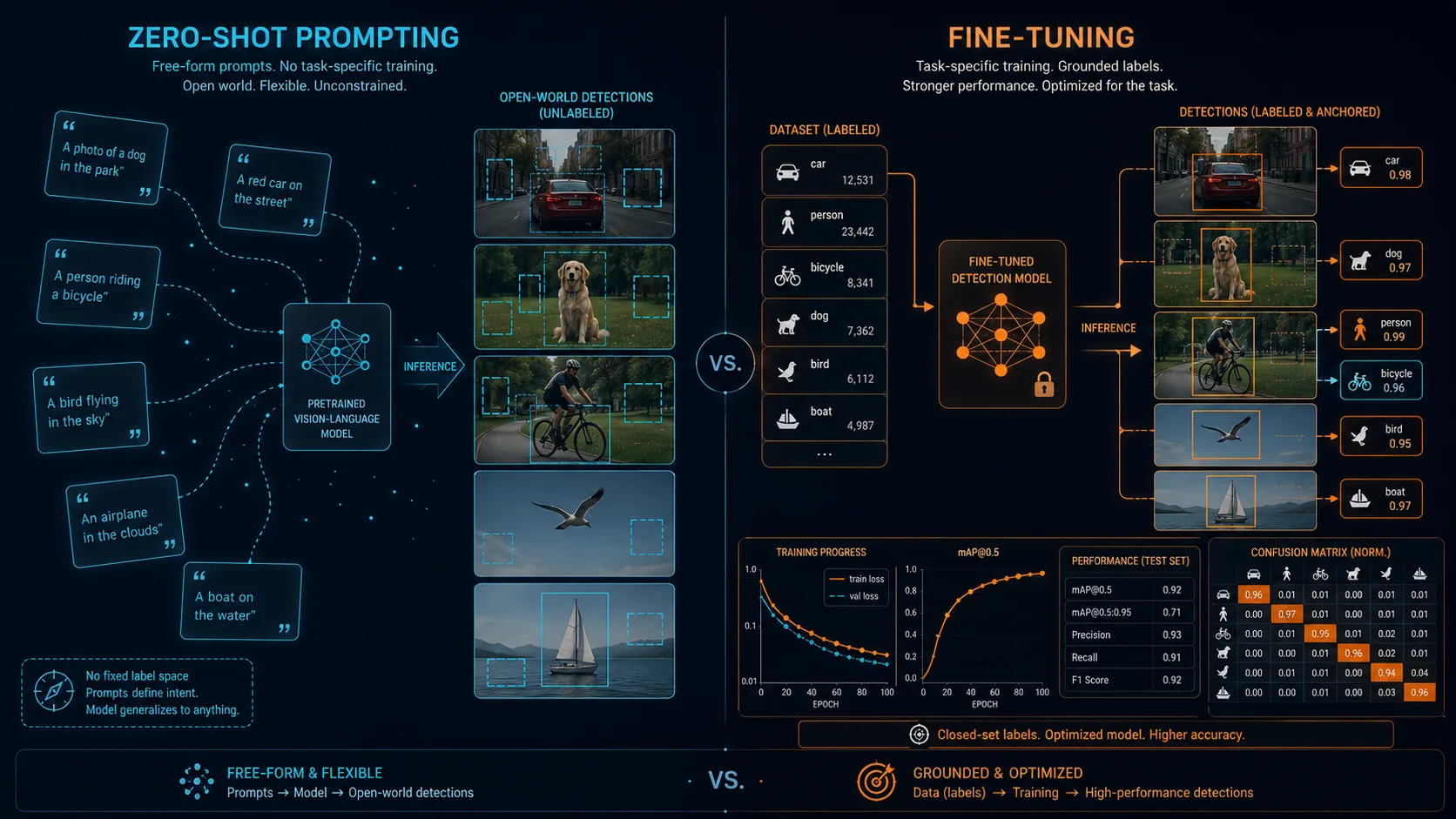
Open-vocabulary 객체 탐지 모델인데 왜 다들 fine-tuning을 다시 한다. YOLO-World — 텍스트 prompt로 임의 클래스를 검출할 수 있다는 게 핵심 셀링 포인트인 모델 — 의 가장 큰 매력은 zero-shot, 즉 학습 데이터 없이 바로 추론이 되는 능력이거든요. 근데 정작 영어권 튜토리얼의 절반 이상은 "YOLO-World를 내 데이터로 fine-tune하는 법"으로 끝남. 두 컨셉이 같은 자리에서 부딪치는데, 왜 이렇게 정리됐는지 좀 따져볼 만함.
Open-vocabulary가 약속한 것
YOLO-World 같은 모델의 약속은 단순함. 미리 클래스를 학습시키지 않아도 "plastic bottle", "person riding bicycle", "broken solar panel" 같은 텍스트만 던지면 그 객체를 감지하는 구조. 이를 위해 모델 안에 vision encoder와 text encoder(보통 CLIP 계열)가 같이 들어가 있고, 이미지 영역 feature와 텍스트 feature를 같은 공간에 매핑함. 클래스를 미리 정의할 필요가 없으니 prototyping이 빠르고, 새 객체가 추가돼도 텍스트만 바꾸면 되거든요.
이 그림 자체는 진짜 매력적임. 작은 PoC 만들 때 "일단 텍스트 던져서 나오는지 보자"가 가능하다는 건 기존 detection 워크플로 대비 압도적인 속도. 라벨링 작업이 처음부터 필요 없다는 게 핵심.
정작 production에서 깨지는 지점
근데 production 직전 단계가 되면 거의 모든 팀이 fine-tuning 쪽으로 빠짐. 이유가 한두 가지가 아님.
첫째, zero-shot 정확도가 도메인 따라 들쭉날쭉. 일반적인 객체(person, car, dog)는 잘 잡지만, 수중에서 떠 있는 plastic 조각, X-ray의 특정 fracture 패턴, 산업 라인의 specific 부품 같은 specialized 도메인에선 정확도가 급격히 떨어짐. 후기들 보면 specialized 도메인에서 zero-shot 정확도가 fine-tune 후 두 배 가까이 뛰는 케이스가 흔함.
둘째, confidence calibration. zero-shot 모드는 confidence score가 도메인별로 일관적이지 않아서, "0.5 이상이면 신뢰" 같은 단순 threshold 정책을 쓰기 어려움. fine-tuning을 거치면 score 분포가 도메인에 맞게 정렬되면서 운영이 단순해짐.
셋째, 추론 속도. open-vocabulary 모드는 inference 시 text encoder를 매번 거쳐야 하는데, 클래스가 고정된 fine-tuning 모드는 vocabulary를 미리 캐싱할 수 있어서 더 빠름. 영상 처리처럼 latency가 중요한 환경에선 무시 못 할 차이.

두 컨셉은 모순이 아니라 단계가 다름
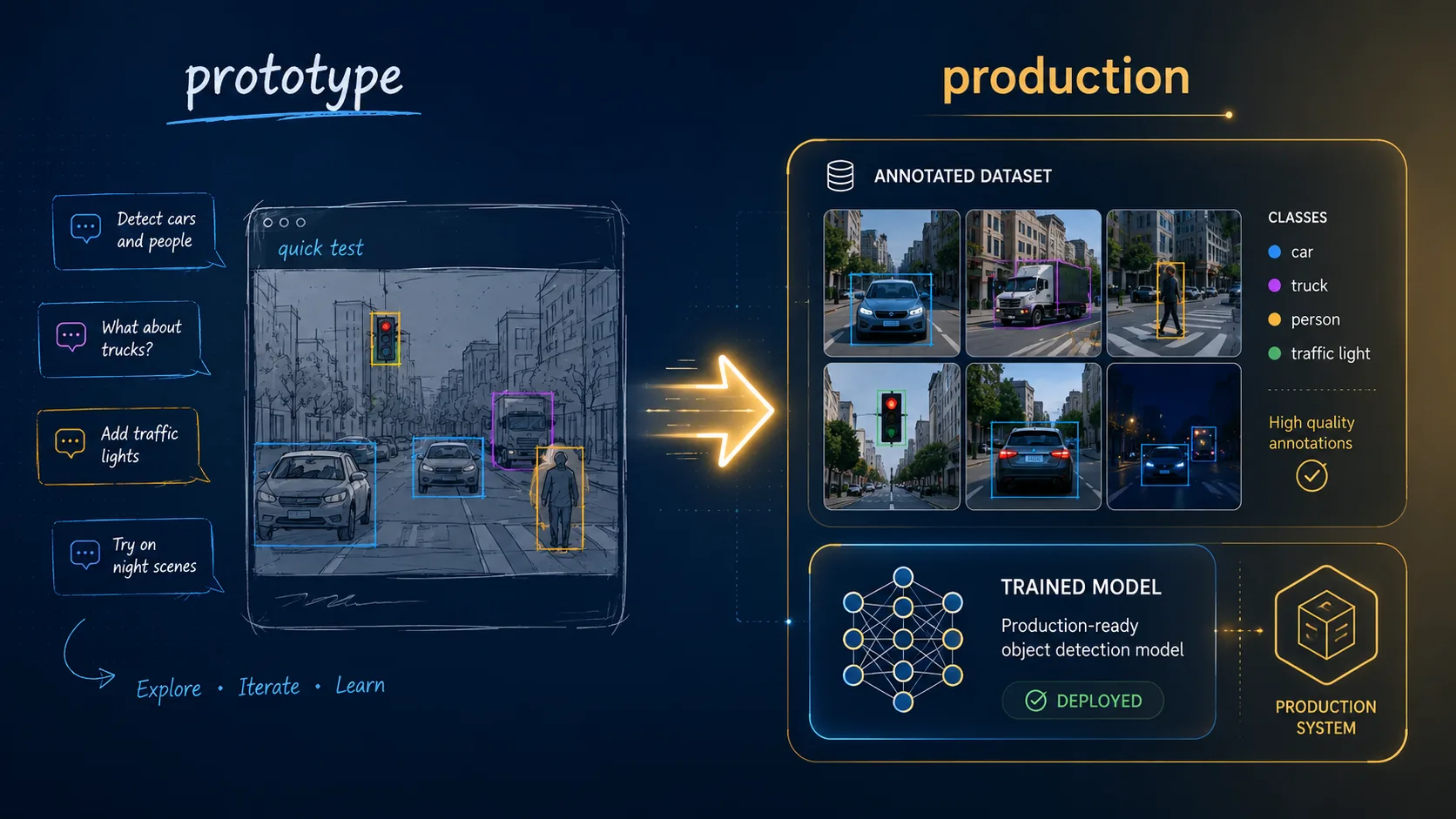
이걸 단계로 보면 모순이 아님. open-vocabulary는 step 1에 적합하고, fine-tuning은 step 2에 적합한 거. PoC와 데이터 수집 단계에서 zero-shot으로 빠르게 라벨링을 가속하고, 어느 정도 데이터가 모이면 fine-tuning해서 production용 모델을 만드는 흐름이 자연스러움. 사실상 open-vocabulary 모델의 가장 큰 가치는 "데이터 수집 단계의 가속기" 역할이거든요. 처음부터 깨끗한 라벨을 다 만들어두지 않아도 되니까.
이 관점에서 보면 fine-tuning 튜토리얼이 자꾸 나오는 건 모순이 아니라 자연스러운 마무리. zero-shot으로 시작 → 가벼운 검수 라벨링 → fine-tune이 표준 워크플로로 정착해 가는 셈.
한국어 도메인에선 fine-tuning이 더 일찍 필요해짐
한국 환경에선 한 가지 더 짚을 게 있음. YOLO-World 안의 text encoder는 대부분 CLIP 계열인데, CLIP은 영어 데이터 위주로 학습됐기 때문에 한국어 텍스트 prompt를 그대로 던지면 zero-shot 정확도가 영어 대비 떨어진다는 얘기를 자주 들음. multilingual CLIP variant가 나와 있긴 하지만 영어 도메인 대비 정확도 차이가 분명히 있음. 직접 한국어 prompt 정확도를 정량 측정한 건 아니라 정확한 수치는 모르지만, 후기들 평균이 그쪽인 듯.
그래서 한국어 라벨로 운영하려면 결국 영어로 라벨링한 뒤 fine-tuning하거나, 한국어 라벨을 학습 데이터에 명시적으로 넣어 fine-tune하는 수밖에 없음. 영어권 튜토리얼은 이 부분을 거의 다루지 않으니 한국 개발자 입장에선 별도로 챙겨야 할 영역.
여담인데 내가 운영하는 aickyway.com이 AI 이미지 생성 쪽이라 객체 탐지를 직접 다루진 않지만, 생성된 이미지의 특정 요소를 추출해야 하는 시나리오에서 zero-shot 검출을 가볍게 돌려본 적은 있음. 영어 prompt로 던졌더니 PoC용으로는 충분히 잡혀서 만족스러웠는데, 같은 객체를 한국어 라벨로 바꾸면 정확도가 눈에 띄게 떨어졌던 기억이 있음. 정량 비교는 안 했어서 정확한 차이는 모름.
한계 / 직접 안 해본 부분
위 내용 중 specialized 도메인에서 zero-shot vs fine-tune 정확도 차이는 직접 measurment한 게 아니라 후기들의 평균에 가까움. 도메인이나 데이터 양, 모델 사이즈에 따라 격차가 더 크거나 작을 수 있음. 한국어 prompt 정확도도 정량 비교 안 해봤기 때문에 약간 걸러 들어야 함. multilingual CLIP variant나 한국어 학습이 강화된 vision-language 모델도 계속 나오고 있어서 시점에 따라 결론이 다를 수 있음.
결론
"open-vocabulary 모델인데 왜 또 fine-tuning이냐"는 잘못된 prism으로 본 질문. zero-shot은 prototyping과 데이터 수집 단계의 가속기고, fine-tuning은 production을 위한 calibration 단계로 이해하는 게 맞음. 두 단계를 합쳐서 보면 워크플로가 명확해짐.
솔직히 영어권 튜토리얼들이 이 두 단계를 명확히 구분해서 설명해주는 경우가 별로 없음. "open-vocabulary 멋지다 → fine-tune 하는 법 보자"로 이어지면서 둘이 동등한 선택지처럼 보이게 됨. 한국 독자한테는 한 번 더 정리가 필요한 부분.
댓글
NEXT_PUBLIC_GISCUS_*환경변수 구성 필요)