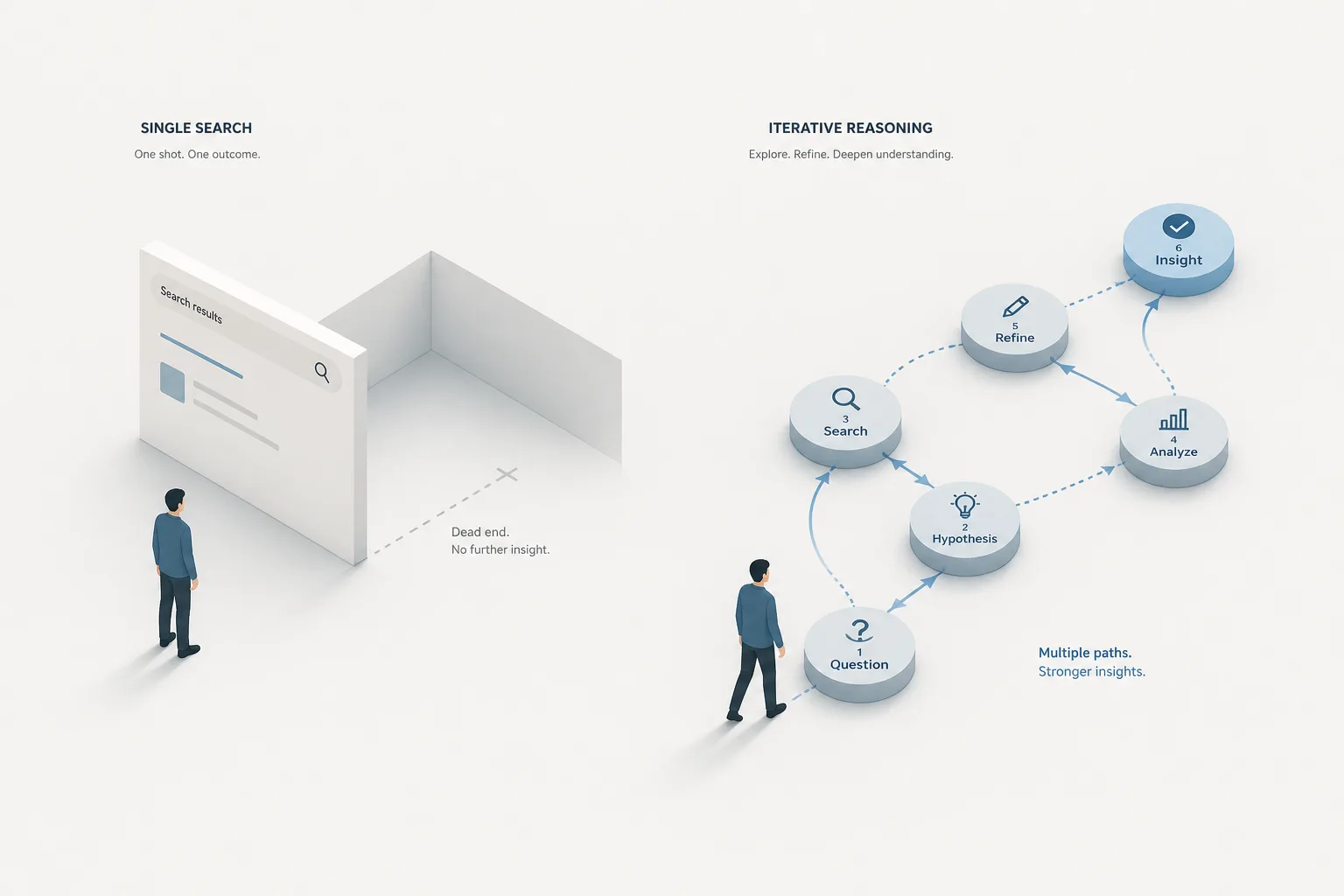
RAG가 산으로 가는 이유는 검색을 한 번만 해서임
단일 RAG가 복잡한 질문에서 답을 못 내는 이유와, 사람의 추론 과정을 닮은 multi-agent self-RAG 패턴 정리. 가설을 세우고 추가 질문을 생성하는 흐름이 왜 효과적인지, 그리고 실서비스에 박을 때 비용·레이턴시·종료 조건 같은 백엔드 입장에서의 현실적인 고민을 같이 풀어봄.
벡터 DB에 문서 박아넣고, 임베딩 뽑고, 코사인 유사도로 top-k 가져와서 LLM한테 던지면 답해주는 구조. 이게 RAG 얘기할 때 가장 먼저 떠올리는 그림인데, 실제 서비스에 박아보면 답이 산으로 가는 경우가 꽤 있음.
문제는 단순함. 사람이 답할 때는 검색 한 번으로 끝내지 않거든요. 일단 자료 보고, 거기서 빠진 정보를 추론하고, 다시 검색하고, 합쳐서 답을 만든다. 단일 검색 RAG는 이 과정의 첫 단계만 흉내내는 거임.
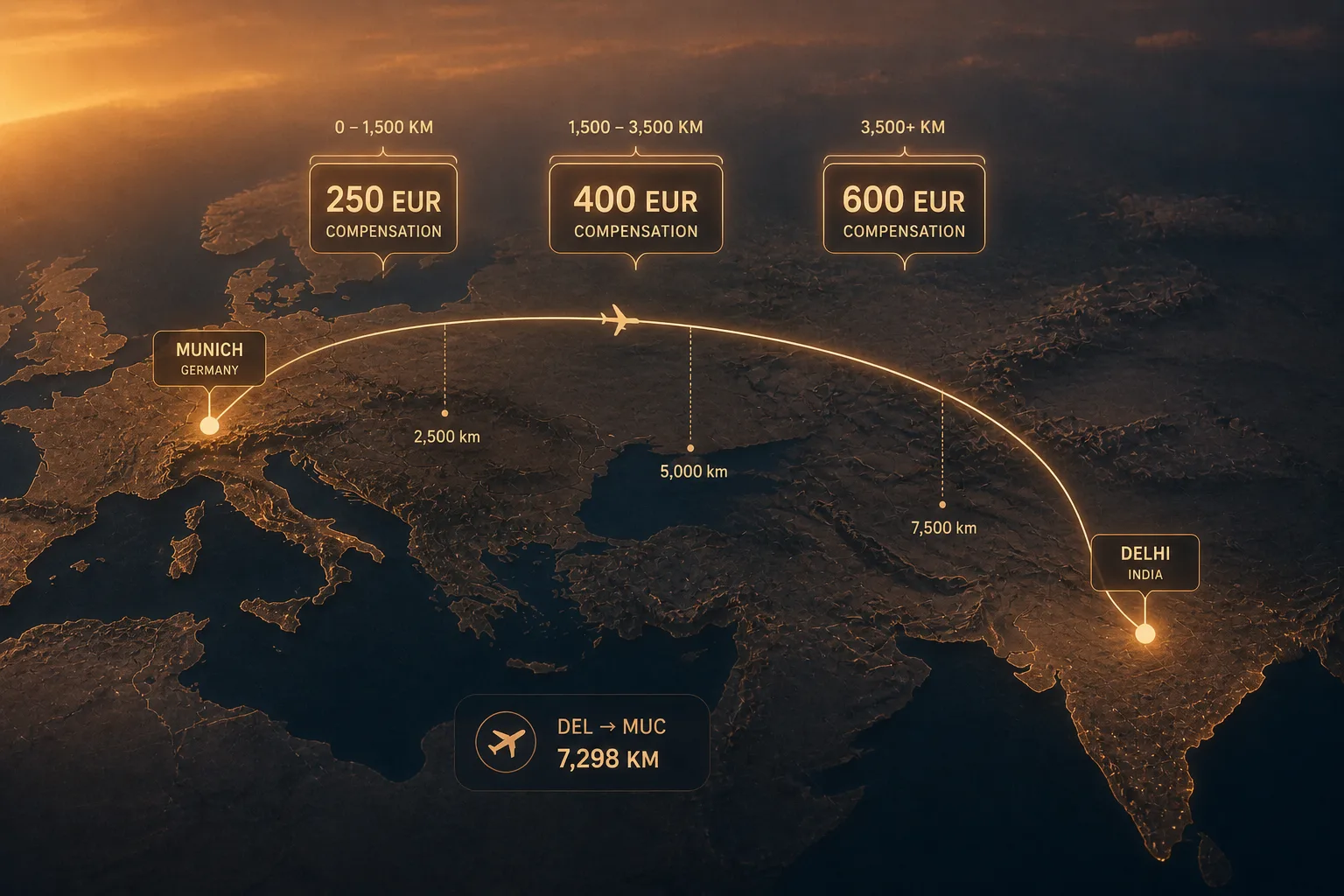
항공 보상금 예시가 직관적임
이런 시나리오를 가정해보자. "델리에서 뮌헨 가는 비행기 탑승 거부당했는데 얼마 받을 수 있음?"
벡터 DB에 EU 항공 보상 정책(EU261) 문서가 들어있고, 검색하면 거리 기준 표가 나옴. 1,500km 이하 250유로, 1,500~3,500km는 400유로, 3,500km 초과 600유로. 근데 정작 델리-뮌헨 거리는 어디에도 없음. 그러니까 단일 RAG는 "거리에 따라 다릅니다, 250에서 600유로 사이입니다" 같은 김빠진 답을 뱉음. 정답은 600유로인데.
사람이 이 자료를 보면 어떻게 함? "거리가 핵심 변수구나"를 인식하고, "그럼 델리-뮌헨이 몇 km지?"를 추가로 검색함. 약 5,900km → 3,500km 초과 → 600유로 확정. 두 번의 검색을 거치면서 답이 완성되는 거임.
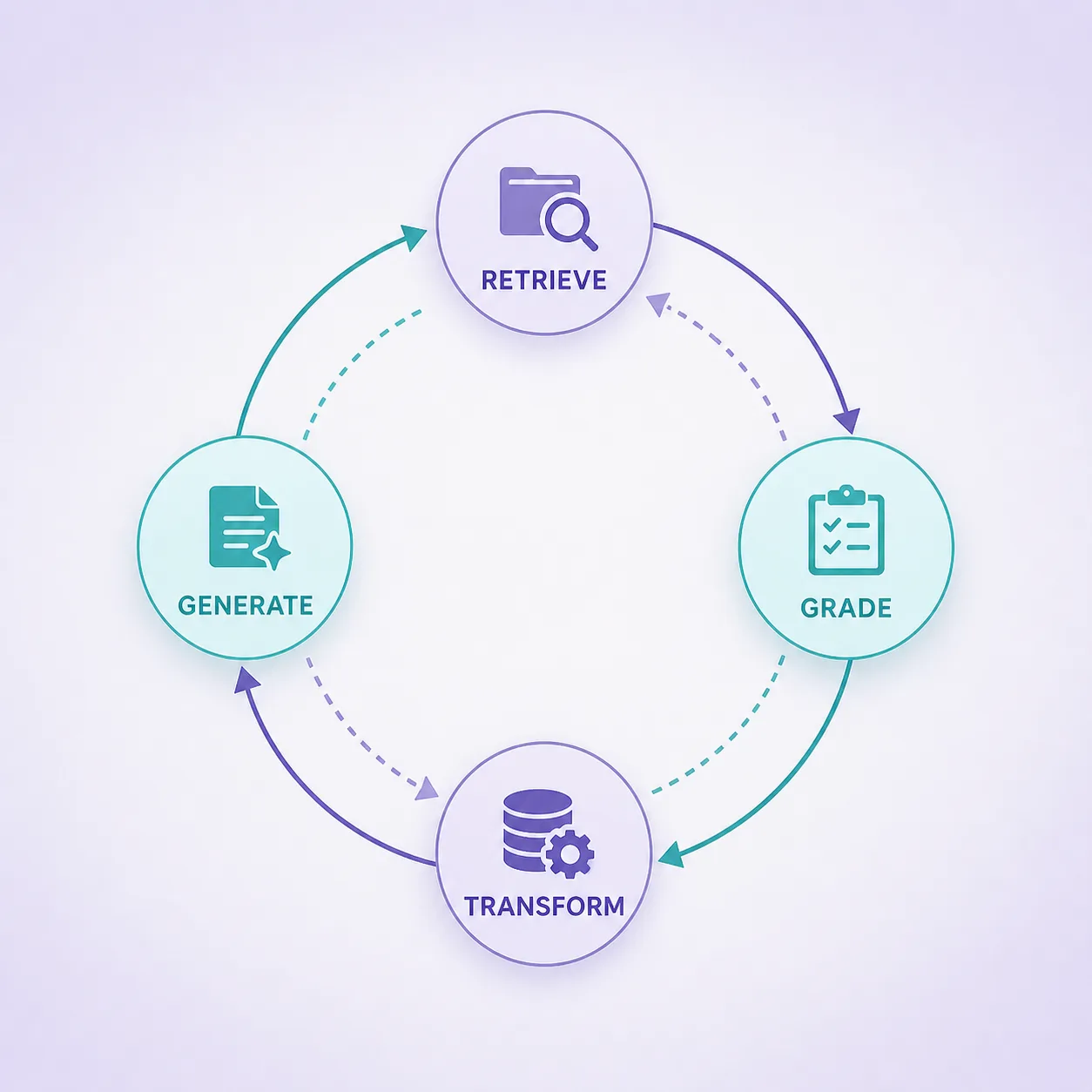
Multi-Agent Self-RAG는 이 흐름을 그래프로 짠 거
핵심 노드는 대충 이렇게 구성됨.
- Retrieve — 일단 검색
- Grade documents — 가져온 문서 중 쓸모 있는 것만 골라내고, 동시에 "이 질문에 답하려면 뭐가 더 필요한지"에 대한 가설(hypothesis)을 세움
- Transform query — 가설을 기반으로 새 질문들을 생성
- 다시 Retrieve — 새 질문으로 또 검색
- Generate — 충분히 모였다 싶으면 답 생성, 부족하면 루프
가장 재밌는 건 grade_documents 단계예요. 단순히 "이 문서 관련 있냐 없냐" 이진분류가 아니라, 관련 없어 보이는 문서에서도 다음에 뭘 물어봐야 하는지 단서를 뽑아낸다. 위 예시에서 거리 기준 보상표가 직접적인 답은 아니지만, "거리를 먼저 알아야 한다"는 가설의 근거가 되는 식이거든요.
이 패턴, LangGraph 같은 그래프 기반 에이전트 프레임워크 덕에 짜기가 꽤 편해진 모양임. 노드끼리 conditional edge로 연결해서 "답이 부실하면 transform_query로 돌아가라" 식의 분기를 자연스럽게 표현 가능.
백엔드 입장에서 걸리는 점
좋아 보이는데, 실서비스 박을 때 신경쓸 게 좀 있어요. 직접 이 패턴 production에 박아본 건 아니고, 흐름만 봐도 이쯤은 걸리겠다 싶은 부분.
비용 — 한 질문당 LLM 호출이 못해도 4~5번 깔고 들어감. grade 한 번, hypothesis 한 번, transform_query 한 번, generate 한 번. 루프 한 바퀴 더 돌면 두 배. Sonnet API 단가를 곱셈으로 생각해야 하는데, 트래픽 좀 붙으면 답변 한 건당 토큰 비용이 단일 RAG의 5배쯤 됨.
레이턴시 — 노드가 직렬이라 응답까지 5~15초는 깔고 감. 채팅 UI에서 streaming으로 중간 단계 노출 안 하면 사용자가 그냥 끊고 나감. "답변 생성 중" 스피너 한참 보고 있을 사람은 별로 없음.
루프 종료 조건 — 원본에서는 "답이 grounded하면 끝, 아니면 다시"인데 실제로는 무한루프 막을 max_iter가 필수. 안 그러면 토큰 비용이 사고 수준으로 튐. 이건 그냥 안전벨트.
관측성 — 답이 이상할 때 어느 노드에서 꼬였는지 추적해야 함. State 단위 로깅 + trace 시스템 안 깔아두면 사후 분석이 지옥. LangSmith 같은 거 안 쓰면 자체로 한 번 짜야 함.
이 중에서 비용·레이턴시는 결국 모든 질문에 multi-agent 안 쓰는 라우팅으로 푸는 게 현실적인 듯. 단순 FAQ류는 단일 RAG로, 진짜 추론 필요한 질문만 multi-agent로 보내는 게이트가 앞단에 필요함. 라우팅 자체에 또 LLM 호출이 들어가긴 하지만, 그건 가벼운 모델로 빼면 됨.

잡담: 그리고 RAG = 벡터 DB라는 등식
요즘 RAG 얘기 나오면 다들 ChromaDB, Qdrant, Pinecone부터 꺼내는데, 정형 데이터가 많은 도메인에서는 그냥 SQL 쿼리가 더 빠르고 정확한 경우가 꽤 있음. 메타데이터 잘 정리된 테이블이 있으면 LLM이 SQL을 직접 작성해서 던지는 구조가 의외로 잘 먹히거든요. RAG = 벡터 검색이라는 등식이 너무 강하게 박혀있는 분위기라, 가끔은 다른 접근도 같이 봐야 함.
내 경우 운영 사이트에서 일부 조회는 벡터보다 그냥 인덱스 잘 깐 SQL이 백 배 나았던 기억이 있음. 도구는 도구일 뿐, 박고 보면 답이 나오는 게 아니라.
정리
multi-agent self-RAG의 핵심 아이디어는 결국 "검색을 한 번에 끝내지 마라"임. 사람이 자료 찾을 때처럼 가설 세우고, 부족한 부분 다시 묻고, 합쳐서 답하라는 거. 이걸 그래프로 표현하면 코드가 의외로 깔끔해짐.
근데 만능은 아니고, 진짜 필요한 질문에만 적용하는 게 맞다. 단순 검색이면 단일 RAG, 추론이 필요한 질문이면 multi-step. 이 구분을 앞단에서 분기시키는 게 다음 과제.

다음에는 LangGraph로 multi-step RAG 흐름을 직접 짜본 코드를 정리해볼 예정이에요. 이번 글은 패턴의 큰 그림이고, 실제 노드 함수 구현이랑 State 관리 디테일은 따로 한 편으로 빼는 게 깔끔할 듯.
댓글
NEXT_PUBLIC_GISCUS_*환경변수 구성 필요)