RAG는 죽었다는 글이 많은데 한국어 환경에서는 좀 다른 얘기
영어권에서 자주 도는 "RAG 파이프라인은 죽었다, 에이전트가 검색이다" 흐름을 한국어 환경 관점에서 다시 따져봤음. hybrid retrieval의 BM25는 한국어 형태소 분석을 별도로 붙여야 하고, 한국어 임베딩 모델 선택지는 영어만큼 풍부하지 않으며, MCP 채택은 한국에서 아직 초기 단계라 영어권 thesis를 그대로 옮기기 어려운 변수들이 붙는다는 정리.
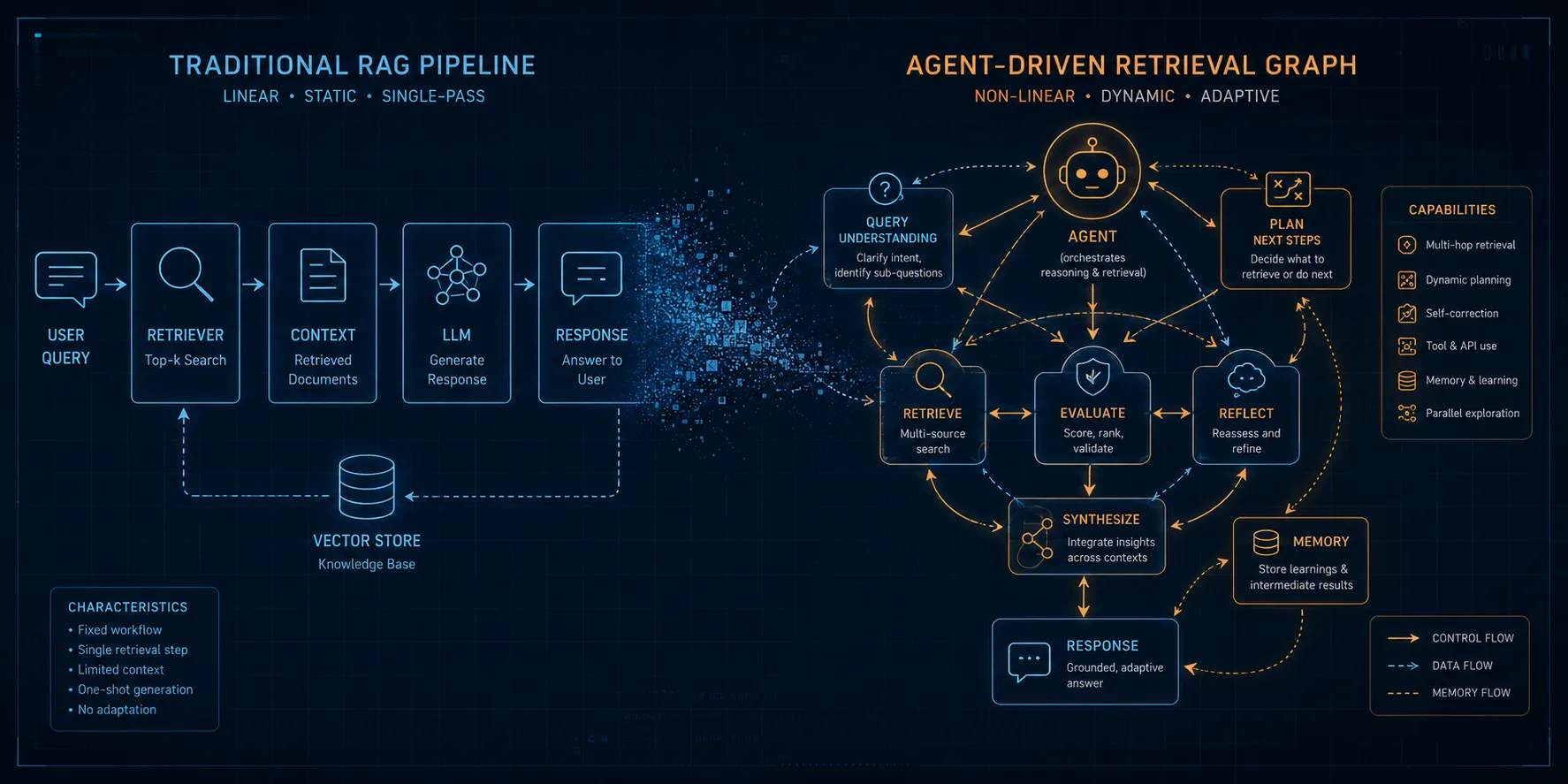
"RAG 파이프라인은 죽었다"는 주장이 영어권 글에서 자주 나옴. 검색은 더 이상 별도 단계가 아니라 에이전트가 도구처럼 호출하는 무엇이라는 얘긴데, 여기에 따라붙는 용어가 hybrid retrieval (BM25와 벡터 검색을 RRF — Reciprocal Rank Fusion이라는 ranking 결합 방식으로 합치기), CRAG (retrieval 결과를 LLM이 직접 평가해서 부족하면 다시 검색하는 self-correcting 패턴), DSPy (prompt를 학습 가능한 파라미터로 다루는 프레임워크) 같은 것들. 그럴듯하게 들리는데, 한국 환경에서도 그대로 적용되는지는 좀 따져봐야 함.
영어권에서 자주 도는 thesis
요즘 RAG 글의 대부분은 비슷한 결론을 공유함. (1) hybrid retrieval이 표준이고, (2) self-correcting loop (CRAG, LangGraph)가 기본이고, (3) DSPy처럼 prompt를 학습 가능한 파라미터로 다루는 게 다음 단계고, (4) MCP가 retrieval을 도구의 한 종류로 환원함.
이 thesis 자체는 합리적임. 영어권 production 환경 후기에서 비슷한 결론이 반복적으로 나오고, 논문이나 LangGraph 공식 docs 같은 자료에서도 뒷받침됨. 다만 한국 환경에서 그대로 받아들이면 한 번씩 걸리는 부분들이 있다는 게 본 글의 출발점.
Hybrid retrieval이 한국어에서 만나는 첫 번째 벽
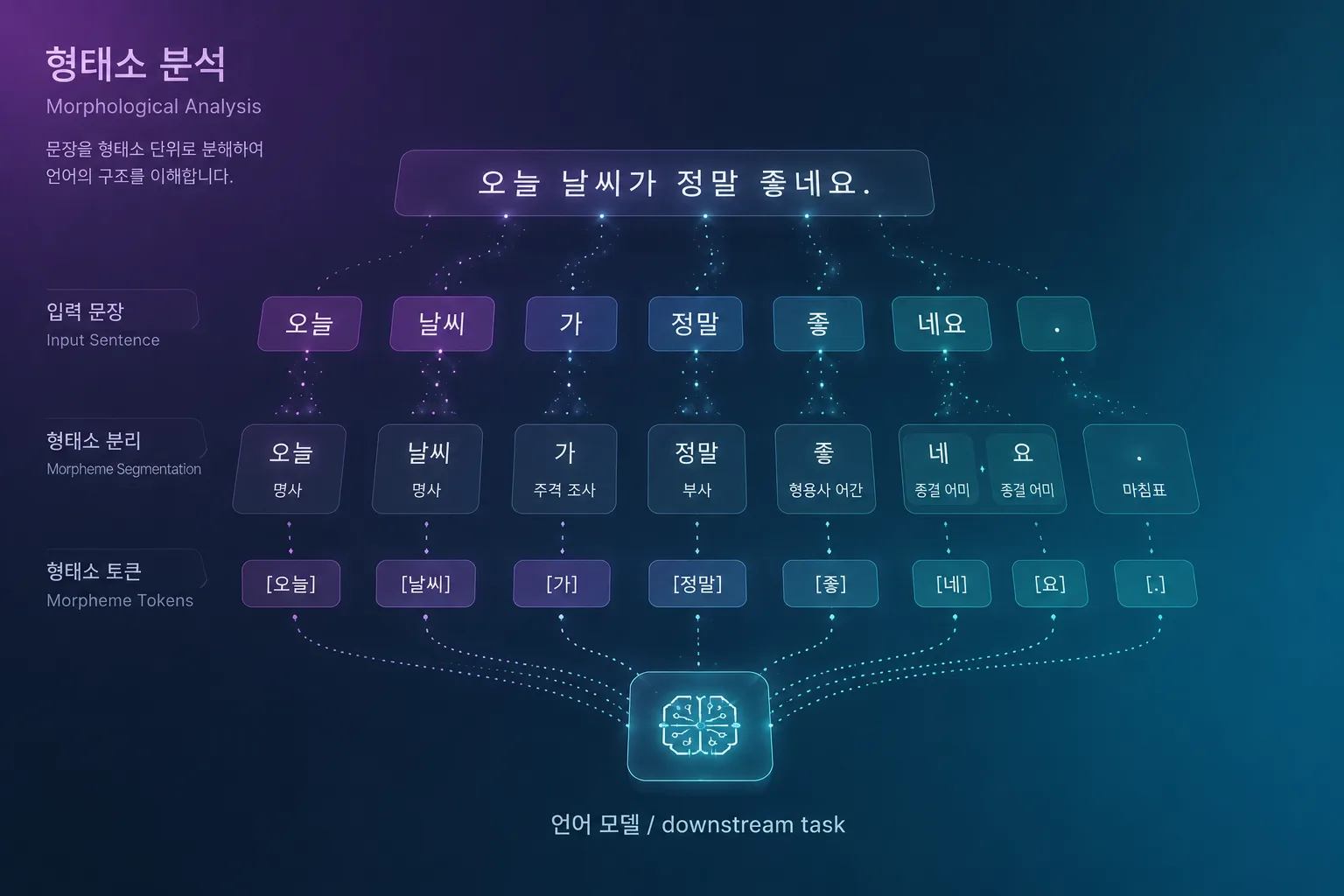
가장 먼저 걸리는 건 BM25임. BM25는 토큰 단위 매칭이 핵심인데, 한국어는 교착어라 형태소 분석 없이는 토큰화가 사실상 안 됨. "계약 해지 절차"를 띄어쓰기 기준으로 자르면 일단 분리는 되지만, "계약을", "계약은", "계약에" 같은 형태가 다 다른 토큰으로 잡혀서 매칭이 깨짐.
그래서 한국어 BM25는 거의 항상 형태소 분석기(Mecab, Komoran, nori 등)를 앞에 붙여야 하고, 이게 추가 인프라 부담이 됨. ElasticSearch에서 nori 분석기 쓰는 식으로 우회는 가능하지만, MongoDB Atlas Search 같은 SaaS에서는 한국어 분석기 옵션이 한정적이라 도입 단계에서 막히는 경우가 자주 있음.
벡터 검색 쪽도 비슷한 함정. 한국어 임베딩 모델 선택지가 영어만큼 풍부하지 않고, 다국어 모델(BGE-M3 같은)을 쓰면 영어 도메인 대비 retrieval 정확도가 살짝 떨어진다는 얘기를 자주 들음. 직접 production 규모로 깊게 올려본 건 아니라 정확한 수치는 모르지만, 후기들 평균이 그쪽인 듯.
CRAG, DSPy — 좋은데 운영 비용이 만만치 않음
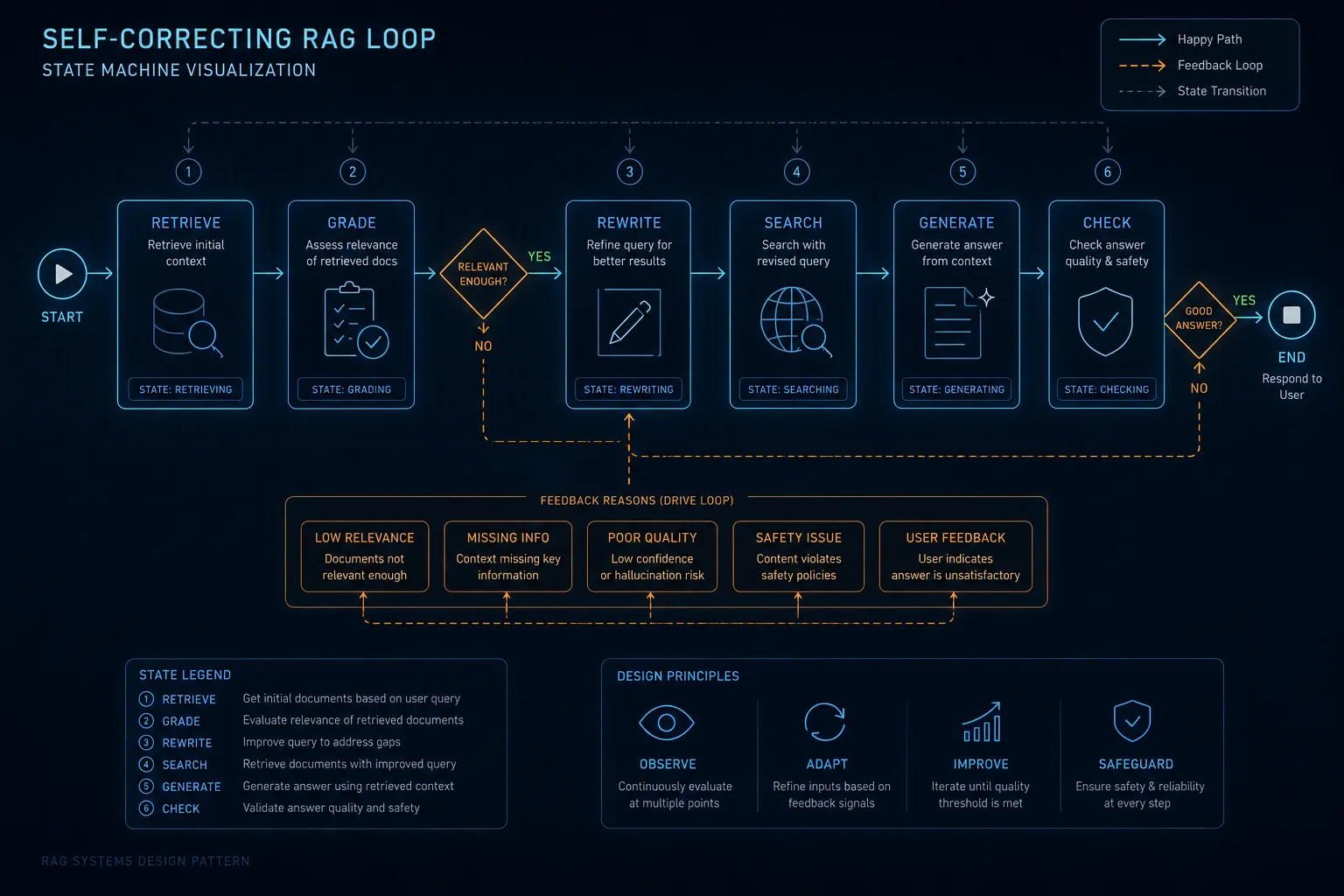
self-correcting loop는 매력적임. retrieval 결과의 quality를 LLM이 직접 grade하고, 부족하면 query를 rewrite해서 다시 도는 구조. hallucination이 줄어드는 효과는 인정.
문제는 호출 비용. 단발 RAG는 LLM 호출이 한 번이지만, CRAG는 grade → rewrite → web_search → generate → hallucination check까지 도는 동안 LLM 호출이 3~5배로 늘어남. 작은 회사에서는 도입 결정 자체가 만만치 않음. 단순한 RAG가 충분한 케이스에서 굳이 self-correcting 넣는 건 over-engineering임.
DSPy는 다른 차원의 매력이 있는데, prompt를 학습 가능한 파라미터로 다루기 때문에 hand-crafted prompt가 사라짐. 이론은 좋음. 다만 학습 데이터셋이 따로 필요하고, MIPROv2 같은 optimizer가 도는 동안 LLM 호출이 또 한 번 폭발하는 게 단점이라고 함. fine-tuning 직전 단계라고 보면 될 듯.
여담인데 내가 운영하는 aickyway.com에서는 RAG를 본격적으로 쓰진 않고, 사용자 prompt history나 이미지 메타데이터 검색에 풀텍스트랑 벡터를 같이 쓰는 정도임. 그래도 한국어 검색 도입할 때 형태소 분석기 셋업에서 한 번씩 시간 까먹는 건 비슷하더라고요.
MCP가 RAG를 도구로 환원한다는 얘기
MCP가 등장하면서 retrieval이 더 이상 고정된 단계가 아니라 agent가 호출하는 여러 tool 중 하나가 되는 그림이 가능해짐. 이론적으로는 깔끔한 설계임. agent가 "이 질문은 retrieval 필요 없음" 판단해서 그냥 답하거나, "이건 web search가 더 적합" 판단해서 다른 tool로 가는 식.
근데 한국 환경에선 MCP 자체의 채택이 아직 초기 단계임. 한국 회사 자료를 retrieval하는 MCP server를 직접 만들어 쓰거나, 영어권 MCP를 한국어 도메인에 맞춰 wrapping하는 작업이 필요한데, 이쪽 reference가 영어권 대비 한참 부족함. 결국 "MCP가 표준"이라는 영어권 흐름을 그대로 옮기기 어렵고, 자체 구현 비중이 더 큼.
한계 / 직접 안 해본 부분
위 내용 중 hybrid retrieval의 BM25 영역은 ElasticSearch + nori 셋업해서 한국어 검색 다뤄본 경험 기반이 있고, RAG 자체를 production 규모로 운영해본 건 아님. CRAG와 DSPy도 토이 단위로만 시도해봤지 회사 데이터에 깊게 적용해본 건 아니거든요. RAGAS 같은 평가 프레임워크도 자료 위주로 본 거라 실제 도입 시 어디가 까다로운지는 별도 확인이 필요한 영역.
또 영어권 글들의 thesis 자체가 영어 데이터·영어 도메인 기준이라는 점도 감안해야 함. 한국어 retrieval은 별도의 평가셋과 다른 trade-off가 필요한데, 이건 영어권 글에서 거의 다뤄지지 않음.
결론
"RAG 파이프라인은 죽었다"는 표현은 좀 과한 marketing 톤. 정확하게 말하면 "단발 retrieval-then-generate 구조는 더 이상 default가 아니다" 정도가 맞음. agent가 검색 결정을 일부 가져가고, hybrid retrieval과 self-correcting loop가 추가되는 흐름은 진짜인데, 이걸 한국어 환경에 그대로 옮기려면 형태소 분석, 한국어 임베딩 모델, MCP 채택 부족 같은 추가 변수가 붙음.
솔직히 한국 회사 RAG는 영어권보다 1.5단계 정도 뒤처져 있음. 이게 단점만은 아닌 게, 영어권에서 반년쯤 더 검증된 패턴만 골라 도입할 수 있다는 뜻이기도 함.
다음에는 한국어 RAG 구축할 때 ElasticSearch nori vs OpenSearch vs Qdrant + 형태소 분석기 같은 조합을 직접 비교해본 후기로 정리해볼 생각임. 영어권 글에는 안 나오는 부분이라 좀 더 실용적인 글이 될 듯.
댓글
NEXT_PUBLIC_GISCUS_*환경변수 구성 필요)