SD3가 SDXL보다 글자 잘 그리는 이유, 데이터 때문이 아니었음
Stable Diffusion 3에서 U-Net이 transformer로 바뀌고 cross-attention 대신 joint attention이 들어간 게 어떤 의미인지, MMDiT 구조를 따라가면서 정리. 이미지 생성 사이트 운영자 입장에서 아키텍처 변화가 출력 품질에 어떻게 묻어나는지, 그리고 구조만 바뀐다고 다 풀리는 건 아니라는 회의까지.
이미지 생성 사이트 운영하면서 SDXL이랑 SD3를 같이 써본 지 좀 됐는데, SD3의 텍스트 정합도가 SDXL과 결이 묘하게 다르다는 느낌은 진작부터 있었음. "stable diffusion은 글자를 못 그린다"가 옛말이 된 게 SD3 즈음인데, 단순히 학습 데이터를 더 부어서 그런 건 아닌 것 같단 막연한 감만 있었거든요. 며칠 전에 MMDiT 블록을 코드 수준에서 풀어놓은 자료 하나를 읽다가, 그 묘함의 출처가 cross-attention 자체를 버린 데 있다는 게 그제서야 와닿더라.
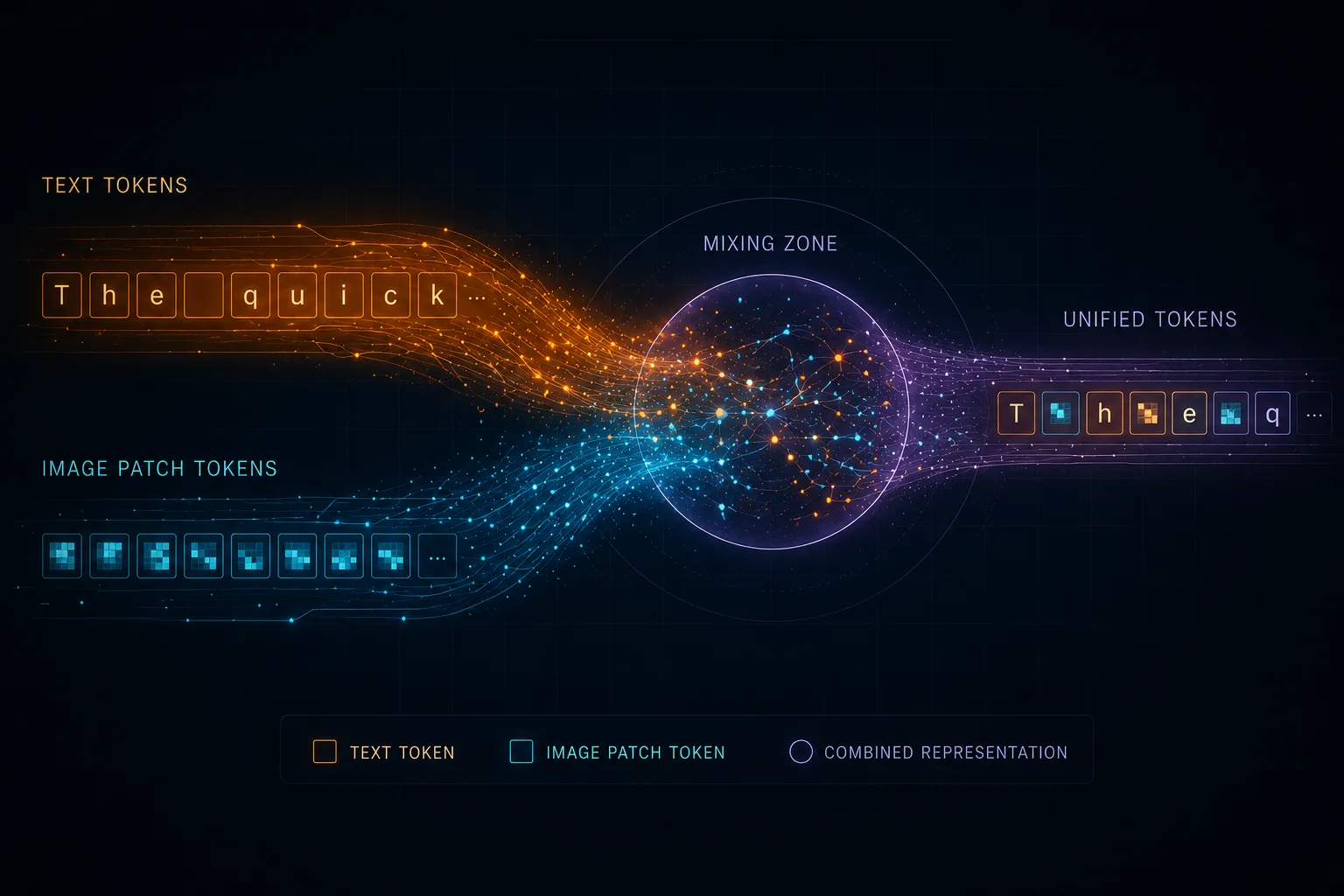
본문에 자주 나올 단어 몇 개를 짧게 짚고 가요. MMDiT는 Multimodal Diffusion Transformer 줄임말, SD3가 채택한 텍스트+이미지를 같이 처리하는 트랜스포머 블록입니다. U-Net은 SD1.5나 SDXL에서 메인 백본으로 쓰던 컨볼루션 네트워크고요. cross-attention은 이미지 token이 텍스트 token을 일방적으로 참조하는 attention 패턴, joint attention은 두 modality를 한 sequence로 합쳐 한 번에 attention 돌리는 방식. 이 4개만 잡고 가면 됨.

U-Net에서 트랜스포머로 — 그림이 통째로 바뀜
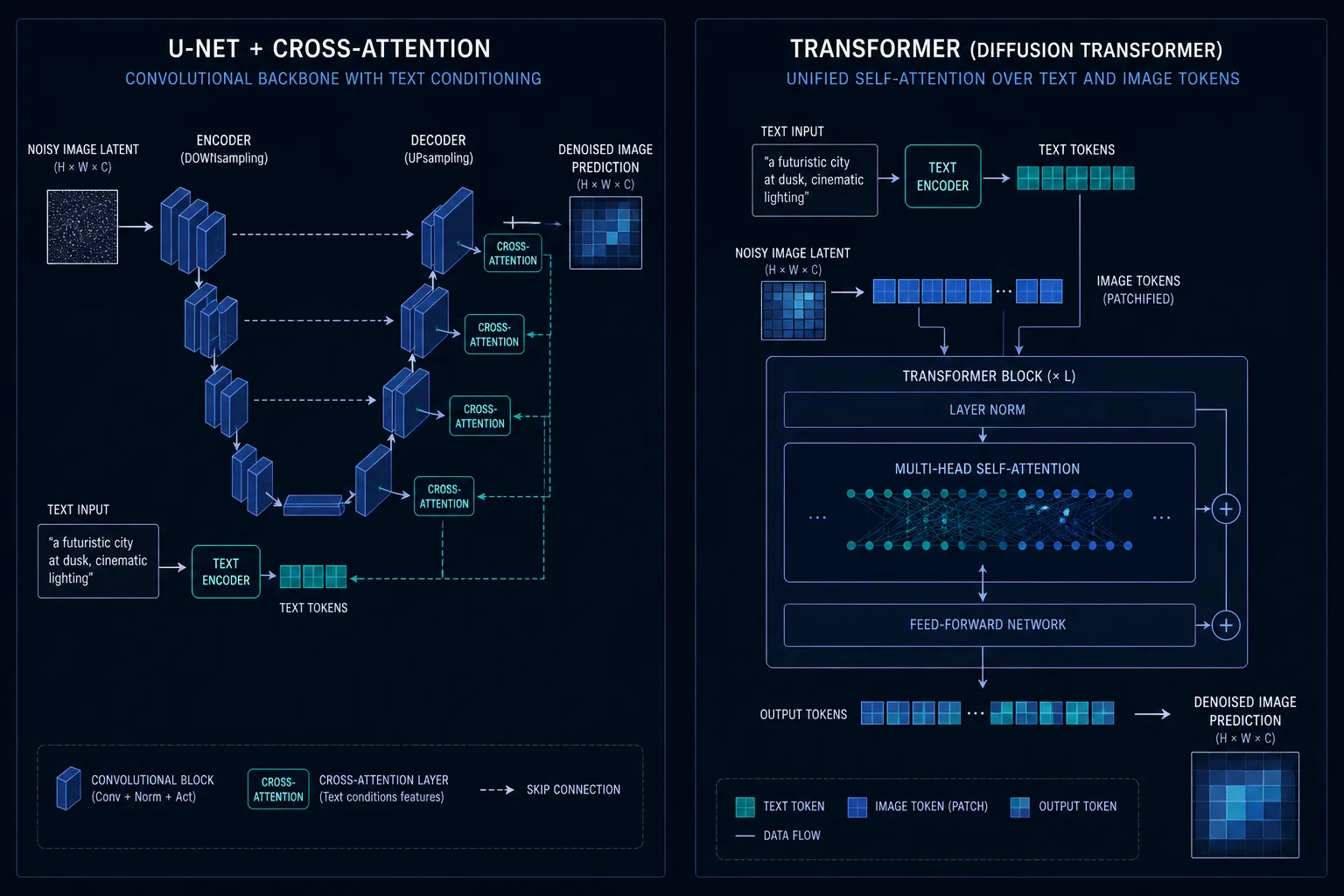
SD1.5, SDXL 시절의 구조는 대충 이런 모양이었어요. 이미지 latent를 컨볼루션으로 깔아두고, 텍스트 임베딩은 따로 들어와서 cross-attention 블록에 던져넣는 식. 메인 흐름은 이미지 쪽이고 텍스트는 "어떤 그림을 그릴지" 알려주는 옆에서 거드는 입력 같은 위치였음. 짧게 말하면 텍스트가 손님이었던 거죠.
SD3의 MMDiT는 이 그림을 통째로 갈아엎습니다. 이미지든 텍스트든 둘 다 token으로 펴서 같은 트랜스포머 안에 던져넣어요. ViT가 이미지를 패치 단위 token으로 자르듯이, MMDiT는 텍스트 token + 이미지 patch token을 하나의 sequence로 꿰는 거. 이쯤 되면 "이미지 모델"이라기보다 "이미지도 처리하는 일반 트랜스포머"에 가까움.
진짜 핵심은 attention을 어떻게 돌리느냐
근데 이게 단순히 트랜스포머로 바꿨다고 끝나는 게 아님. 그 안에서 attention을 어떻게 돌리느냐가 결정적인 차이거든요. 직관적으로는 self-attention(이미지↔이미지) + cross-attention(이미지↔텍스트) 두 개를 따로 돌리면 될 것 같은데, MMDiT는 그렇게 안 합니다.
대신, 텍스트 token이 자기 Q, K, V를 뽑고 이미지 token도 자기 Q, K, V를 뽑은 다음, 둘을 sequence 차원에서 concat 해버려요. 그리고 attention 한 번. 이미지 token이 다른 이미지 token과 attention 하면서 동시에 텍스트 token과도 같은 연산 안에서 attention 하는 거. 분리된 두 단계가 아니라 한 매트릭스 안에서 정보가 섞임.
cross-attention과의 결정적 차이가 여기서 나옵니다. cross-attention은 "이미지가 텍스트를 본다"는 단방향이거든요. joint attention은 "텍스트와 이미지가 서로를 본다". 그래서 텍스트 representation이 layer를 지나면서 이미지에 영향받아 dynamic하게 바뀜. 텍스트 임베딩을 한 번 박아놓고 가만히 두는 게 아니라, 매 블록마다 같이 진화하는 거죠.
이거 별 거 아닌 것 같지만 의미는 큼.
AdaLN 게이팅이 조용히 일하는 부분
한 가지 더 짚어둘 게 AdaLayerNorm + gating 패턴. 트랜스포머 블록마다 conditioning 정보(timestep, text 평균 임베딩 등)로부터 layer norm의 shift, scale, 그리고 gate를 만들어내서 출력에 곱하는 구조거든요. 단순히 x = x + update가 아니라 x = x + gate * update인데, gate 값을 모델이 학습해서 "지금 이 블록의 업데이트를 얼마나 받아들일지"를 스스로 조절합니다.
이게 학습 안정성이랑 스케일링에 꽤 결정적이라는 얘기가 후속 논문들에서 반복적으로 나오는데, 직접 from scratch로 짜본 건 아니라서 어디까지 사실인지 단언은 못 하겠고. 공식 논문(arxiv: Scaling Rectified Flow Transformers)이랑 후기 종합하면 그렇다는 정도.
운영자 입장에서 와닿는 부분
이미지 생성 서비스 굴리는 입장에서 이 변화가 흥미로운 건, 텍스트 정합도가 좋아진 게 단순히 "더 큰 텍스트 인코더 썼다"가 아니라 attention 설계 자체에서 나온다는 점이거든요. SDXL도 텍스트 인코더를 두 개 붙이는 식으로 보강은 했는데, cross-attention 구조 안에선 어쨌든 텍스트가 손님인 건 변하지 않았어요. SD3가 글자 정합도, 다중 객체 처리, 복잡한 프롬프트 해석에서 한 단계 올라간 데에는 이 구조 변화 영향이 작지 않다고 봄.
다만 추론 속도엔 그닥 좋은 소식이 아닙니다. 이미지 token + 텍스트 token이 한 sequence가 되니까 attention 연산 비용이 (이미지 토큰 수 + 텍스트 토큰 수)² 으로 커져요. 고해상도일수록 토큰 수가 많아지니 부담이 더 커지고. 내 환경이 RTX 3090이라 SDXL 돌리던 감으로 SD3 돌리면 좀 무겁다는 감각이 있음.
한계 — 한 발짝 떨어져서 보면
직접 MMDiT 블록을 from scratch로 짜본 건 아니어서, "joint attention이 정말 cross-attention보다 나은가"라는 본질적 질문엔 코드 한 줄로 대답할 입장은 못 됨. 후기랑 벤치 보면 joint attention이 이기는 분위기인데, 이게 attention 설계 덕분인지 그냥 트랜스포머 자체의 scaling 덕분인지는 분리하기 어렵습니다. SD3 vs SDXL 단순 비교는 백본 + attention + 데이터 + 학습 compute가 다 다르니까요.
한 가지 더, "트랜스포머로 갈아타면 만사 OK" 식 narrative도 좀 걸러 들을 필요가 있음. FLUX, DALL-E 3, Imagen 등 트랜스포머 계열이 주류로 올라간 건 맞는데, 그들이 잘 되는 이유엔 데이터 품질, 캡셔닝, 학습 자원이 같이 묻혀 있어서 attention 설계만으로는 설명이 안 돼요. 작은 모델 사이즈에서 joint attention의 이점이 얼마나 의미 있는지도 별로 검증된 게 없는 듯하고. 이 부분은 좀 더 봐야 할 듯.
살짝 옆길 — 이미지 모델이 LLM 쪽으로 수렴하는 중
여담인데 요즘 이미지 생성 모델들이 점점 LLM 구조 쪽으로 수렴하는 게 흥미롭습니다. ViT가 컨볼루션 자리를 차지한 게 5년 전쯤이고, 이제 이미지 생성 백본도 트랜스포머로 옮겨갔어요. attention 설계, layer norm 게이팅, conditioning 방식 다 LLM 계보에서 가져온 거. 그만큼 모달리티 사이 경계가 흐려지는 중인 듯한데, 단일 트랜스포머가 텍스트, 이미지, 비디오 다 처리하는 시대가 정말 가까워 보이네요. 이게 backend 입장에선 servable artifact가 한 종류로 줄어든다는 의미라 인프라 측면에서도 반가움.

정리
MMDiT의 핵심을 한 줄로 줄이면 "텍스트와 이미지를 같은 attention 안에서 본다"는 점, 이거 하나로 정리됩니다. cross-attention의 단방향성을 깨고 양방향 information flow를 만든 거. 이게 SD3가 이전 모델 대비 텍스트 정합도, 복잡한 프롬프트 처리에서 한 단계 올라간 한 가지 핵심 이유라고 보고요. 다만 추론 비용은 더 비싸지니까 production 입장에선 트레이드오프 잘 봐야 함. 가벼운 응답이 필요한 시나리오엔 SDXL이 여전히 훨씬 합리적인 선택임.
댓글
NEXT_PUBLIC_GISCUS_*환경변수 구성 필요)