로컬 LLM 도구 비교 글이 자주 비슷한 결론으로 가는 이유
영어권 개발자 블로그에서 자주 보이는 Ollama·LM Studio·Jan 비교 글들이 결국 같은 결론으로 흘러가는 패턴을 짚고, 그 안에서 빠져 있는 모델 선택·fine-tuning·한국어 품질 문제를 한국 개발자 관점에서 정리. 도구 비교는 30%, 진짜 차이를 만드는 건 모델과 운영 시나리오 70%라는 게 핵심.
요즘 영어권 개발자 블로그에서 "AirLLM·Ollama·LM Studio·Jan 비교" 같은 글이 부쩍 자주 보임. 한두 개만 봐도 어떤 결론이 올지 예측이 됨. "개발자면 Ollama, GUI 원하면 LM Studio, 어시스턴트 원하면 Jan"으로 거의 수렴하거든요. 근데 이 글들 한참 보다 보면 이상한 점이 있음. 왜 다들 비슷한 결론으로 끝나는 걸까.
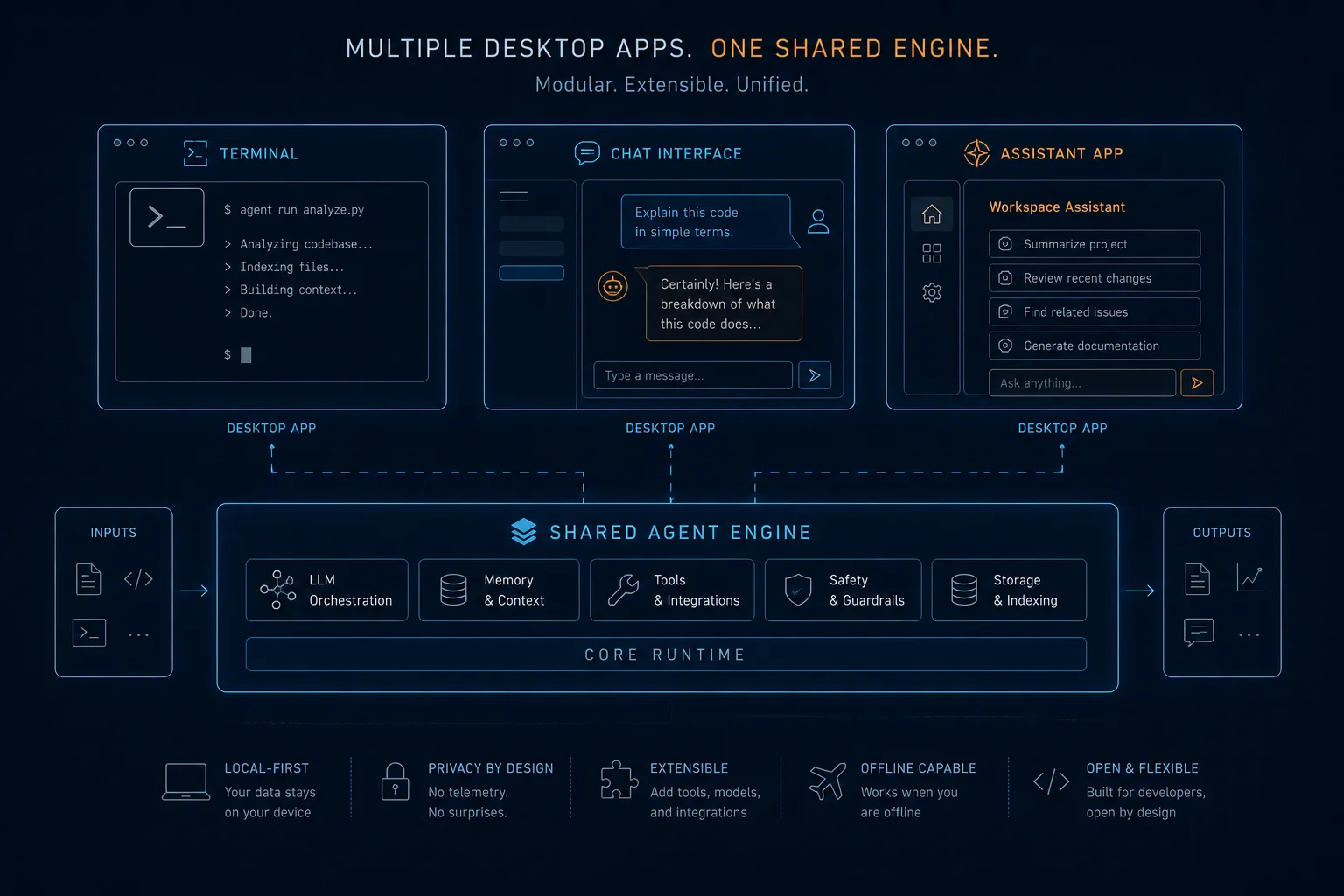
본문에 자주 나올 도구 이름부터 짚고 가는 게 낫겠음. Ollama는 CLI 한 줄로 LLM을 띄우는 단순한 실행기고, LM Studio는 ChatGPT 비슷한 GUI 데스크탑 앱. Jan은 거기서 한 발 더 나아간 "로컬 어시스턴트" 형태의 앱이고. 그리고 이 셋이 기본적으로 공통으로 의존하는 추론 백엔드가 llama.cpp.
결론이 비슷한 진짜 이유
이게 우연이 아님. Ollama, LM Studio, Jan 모두 내부적으로는 llama.cpp 또는 그 fork·wrapper를 추론 엔진으로 씀. Ollama는 자체 변형 버전을 쓰고, LM Studio는 거의 그대로 가져다 쓰며, Jan은 Cortex라는 자기네 wrapper 안에 llama.cpp를 두고 있음. 같은 엔진을 다른 UX로 감싸 파는 구조거든요.
이 말은 같은 모델, 같은 quantization, 같은 GPU에서 추론 속도 차이가 거의 안 난다는 뜻임. UX는 다르지만 성능 자체는 사실상 동일함. 그러니 비교 글이 결국 "취향에 맞춰 골라"로 흘러가는 게 자연스러운 거. 문제는 이 패턴 안에서 정작 중요한 질문들이 사라진다는 점임.
정작 빠져 있는 것들
도구 비교 글들이 거의 다루지 않는 항목들이 있음.
모델 선택. 어떤 모델을 띄우느냐가 어떤 도구로 띄우느냐보다 압도적으로 중요함. Llama 3 8B를 코딩에 쓰는 것과 Qwen2.5 Coder 7B를 코딩에 쓰는 건 완전 다른 경험이거든요. 도구 비교 글은 이 차이를 거의 다루지 않고 "일단 llama3 띄우자" 수준에서 멈춤.
fine-tuning과 LoRA 적용. 회사 환경에서 로컬 LLM을 본격적으로 쓰려면 결국 도메인 데이터로 파인튜닝해야 하는데, Ollama는 GGUF 모델만 받기 때문에 학습 후 변환 과정이 추가됨. LM Studio랑 Jan도 마찬가지. 이 부분은 비교 글에서 거의 안 보임.
MCP 지원. 요즘 Anthropic이 밀고 있는 MCP를 로컬 LLM에 붙일 수 있는지가 점점 중요해지고 있는데, 이쪽도 도구마다 성숙도 차이가 큼. Ollama 쪽은 community wrapper가 빠르게 붙고 있고, 나머지는 직접 만들어야 하는 경우가 많다는 얘기를 들음. 직접 다 비교해본 건 아니라 정확한 건 모르겠음.

한국 개발자 관점에서 한 가지 더
한국어 모델 지원이 또 따로 중요함. EXAONE이나 한국어 fine-tuning이 잘 된 7B급 모델들을 GGUF로 변환해 띄우는 워크플로는 영어권 비교 글에서 다뤄지지 않거든요. 그래서 "Ollama 추천!"이라는 글만 보고 도입하면 정작 한국어 출력 품질에서 막힐 수 있음. 이건 도구 문제가 아니라 모델 문제인데, 비교 글들이 이 둘을 분리하지 않음.
여담인데 내가 운영하는 aickyway.com이 AI 이미지 생성 쪽이라, LLM은 프롬프트 보완이나 메타데이터 정리 정도에만 씀. 그래도 로컬에서 돌리면 외부 API 비용이 그대로 사라지는 게 작은 사이드 프로젝트엔 의외로 큰 차이임. 매달 결제하던 게 없어지는 느낌이 묘하게 좋더라고요.

한계 / 직접 안 해본 부분
위 내용 중 도구별 MCP 성숙도나 fine-tuning 워크플로 디테일은 4개 도구를 동일 시나리오로 직접 비교해본 게 아니라 후기들의 평균에 가까움. 좀 걸러 들어야 함. 또 같은 모델·같은 양자화에서 도구별 추론 속도가 정말 동일한지도 환경 변수가 많아서 케이스마다 결과가 갈릴 수 있음. 이걸 진지하게 측정하려면 같은 머신에서 4개를 모두 띄우고 token/s를 재봐야 하는데, 현실적으로 그렇게 정렬된 비교 글은 영어권에서도 잘 안 보임.

결론
도구 비교 글이 의미 없는 건 아님. 처음 진입할 때 어떤 UX가 자기한테 맞는지 파악하는 데는 충분히 도움됨. 다만 "이 도구가 더 좋다"는 식의 결론은 좀 위험함. 본질은 거의 같은 엔진을 다른 옷 입혀 파는 거고, 진짜 비교가 시작되는 지점은 모델 선택, 도메인 데이터 학습 가능성, 한국어 품질, 통합 워크플로 같은 데임.
솔직히 도구 선택이 30%, 모델 선택과 운영 시나리오가 70%. 이 비율이 거꾸로 뒤집힌 글이 너무 많음.
댓글
NEXT_PUBLIC_GISCUS_*환경변수 구성 필요)