Nemotron 3 Nano Omni — 모델 자체보다 인코더 합치는 방식이 더 흥미로움
NVIDIA의 새 omni-modal 모델 Nemotron 3 Nano Omni 발표. 30B 총 파라미터에 3B 액티브, 컨슈머 GPU에 INT4로 올릴 수 있다는 점도 화제지만, 진짜 흥미로운 부분은 모달리티별 best-of-breed 인코더를 얇은 projector로 합치는 reference architecture. 그리고 omni-modal 발표 때마다 반복되는 패턴에 대한 회의적인 메모.
NVIDIA가 며칠 전 Nemotron 3 Nano Omni라는 omni-modal 모델을 오픈 웨이트로 풀었음. 30B 총 파라미터에 3B 액티브, 256K 컨텍스트, 텍스트·이미지·오디오·비디오를 한 번의 forward pass로 처리. 화려한 throughput 수치(비디오 추론 9.2배, 멀티문서 추론 7.4배 등)도 같이 풀렸고요. 근데 발표 자료 몇 개 읽고 든 생각은, 진짜 흥미로운 건 모델 자체가 아님. 합치는 방식과 그게 가능해진 하드웨어 조건, 이 두 가지가 더 의미있는 헤드라인이라고 봅니다.
본문 전에 용어 몇 개만.
- MoE (Mixture of Experts): 여러 전문가 모듈 중 토큰마다 일부만 활성화하는 구조
- A3B (Active 3B): 총 30B 중에서 매 forward pass에 실제 동원되는 파라미터가 3B
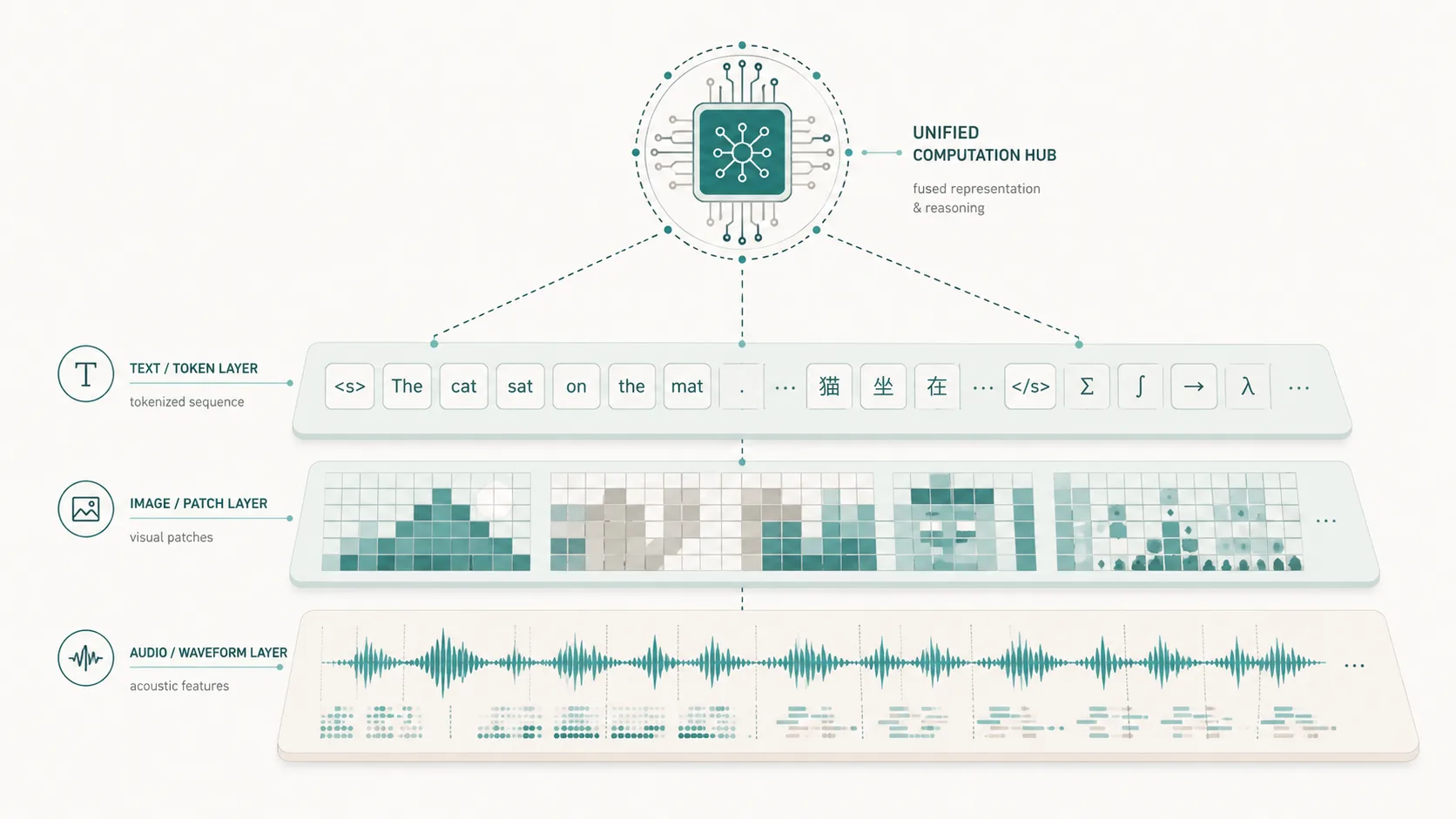
- 인코더 / projector: 이미지·오디오를 LLM이 다룰 토큰으로 바꾸는 게 인코더, 그 출력을 LLM 입력 차원에 맞춰주는 얇은 MLP가 projector
무엇을 합친 건가
세 개의 기존 SOTA 컴포넌트를 그대로 가져다 붙임.
- NemotronH (백본): hybrid Mamba-2 + attention + MoE 구조의 30B-A3B 언어 모델
- C-RADIOv4-H (비전 인코더): CLIP·DINOv2·SAM 같은 여러 비전 SOTA를 distill해서 합친 모델
- Parakeet TDT (오디오 인코더): Hugging Face Open ASR Leaderboard 상위권, 스트리밍 지원
이 셋을 2-layer MLP projector 두 개로 붙이는 게 끝임. NVIDIA가 새 인코더를 처음부터 만든 게 아니라, 각 modality에서 이미 가장 잘하는 모델을 가져다 합쳤다는 게 핵심.

A3B의 경제학
30B 총 파라미터에 액티브 3B라는 숫자가 실용적으로 가장 큰 변화임. INT4로 양자화하면 24GB 컨슈머 카드 — RTX 3090이나 4090 — 에 올라간다고 합니다. 본인 머신이 RTX 3090이라 사양 계산상은 맞는 듯한데, INT4로 직접 띄워본 건 아니라 실제 토큰 속도나 메모리 여유는 더 봐야 할 듯.
근데 이게 사실이라면 의미는 명확함. 그동안 omni-modal perception은 클라우드 API로 굴려야 하는 워크로드였거든요. 30B 클래스 추론 능력을 컨슈머 GPU 한 장에 띄울 수 있다는 건, 그 워크로드가 본인 서버 한 장으로 옮겨갈 수 있다는 의미임. 1인 빌더 단가 계산이 완전히 달라짐.
합치는 방식이 reference architecture
이 패턴 자체는 백엔드 풀스택 입장에서 익숙한 그림이거든요. 데이터를 한 DB에 다 때려박지 않음. MSSQL은 트랜잭션, MongoDB는 문서, Redis는 캐시, Elasticsearch는 검색 — 각자 잘하는 거 따로 두고 thin glue로 붙입니다.
ML 모델 아키텍처가 같은 결론에 도달했다는 게 좀 신선함. 한동안은 "처음부터 끝까지 한 모델로 엔드투엔드 학습"이 정석처럼 보였는데, 이번 사례는 modality마다 분업하고 얇은 projector로 합치는 게 실용적으로 더 좋다는 답을 보여줌. 본인 비전 타워를 처음부터 학습하는 건 한계 효용이 거의 0이라는 거. 이거 그냥 정답임.
회의적으로 봐야 하는 부분
근데 omni-modal 발표 때마다 비슷한 스토리가 반복돼왔음. GPT-4V도, Claude vision도, Gemini multimodal도 처음엔 "이제 모든 modality를 하나로"라고 나왔는데, 실제 production에서는 specialized stack을 그대로 쓰는 케이스가 더 많은 듯하더라고요. 직접 다 production에 올려본 건 아니지만 후기들 보면 그런 흐름.
이유가 있음. omni 모델이 평균적으로 잘해도 개별 modality에서는 specialized 모델이 여전히 우세인 경우가 많거든요. ASR만 보면 Whisper 대비 큰 차이 없거나 더 나쁜 경우도 있고, 차트만 읽으면 ChartQA-tuned 모델이 더 정확함. omni의 진짜 매력은 joint reasoning이지 개별 modality 절대 성능이 아님. "화면 녹화 + 통화 오디오 + CSV를 동시에" 같은 워크플로우에서만 진짜 우위가 나옴.
또 — 발표 자료의 "6개 omni leaderboard 1위"는 omni 모델끼리 줄세운 거지 비전 SOTA, ASR SOTA랑 정면으로 붙은 게 아님. 자기 카테고리 안 1등이라는 거랑 절대 강자라는 건 다름. 이걸 구분 안 하고 마케팅 그대로 받아들이면 production에서 뒤통수 맞을 수 있음.

잡담
aickyway.com 같은 이미지 생성 사이트 운영하는 입장에서 omni 트렌드가 직접적이진 않음. 우리는 만드는 일을 하지 이해하는 일을 하지는 않으니까요. 인접 영역이긴 해서 사용자 업로드 레퍼런스 이미지를 분석해서 자동으로 프롬프트 추천하는 기능 같은 데에는 쓸 만할 수도 있겠다 싶긴 함. 직접 붙여본 건 아니라 가설 수준임.
정리
진짜 가치는 30B-A3B나 9.2배 throughput 같은 숫자가 아님. 두 가지에 있음. 첫째, 모달리티별 best-of-breed 인코더 + 얇은 projector + 작은 MoE 백본의 reference architecture를 오픈 웨이트로 풀었다는 점. 둘째, 30B 클래스를 컨슈머 GPU 한 장에 올리는 시대로 넘어왔다는 점. 본인 시스템 만들 때 각 컴포넌트가 왜 best-of-breed인지 설명할 수 있어야 함. 못 하면 그냥 이거 쓰는 게 답이지.
Nemotron 3 Nano Omni 모델 카드랑 build.nvidia.com NIM 엔드포인트는 같이 두고 보면 됩니다.

댓글
NEXT_PUBLIC_GISCUS_*환경변수 구성 필요)