Claude Code 4.7 올리고 청구서 2배 된 진짜 이유
Sonnet 4.7로 업그레이드한 뒤 Claude Code 토큰 사용량이 갑자기 폭증했다면, 모델 탓이 아닙니다. 진짜 원인은 백엔드 MCP 서버가 컨텍스트 윈도우에 쓰레기를 자꾸 부어넣는 구조. 실측 벤치마크와 InsForge 같은 컨텍스트 엔지니어링 도구로 토큰비 2~3배 줄이는 구조를 정리했어요.
지난달 Claude Code 청구서 보고 한 5초 정도 멈췄어요. Sonnet 4.6에서 4.7로 올린 직후였는데, 평소 작업량이 거의 같은데 토큰이 1.8배 찍혀 있더라고요. 처음엔 "아 4.7이 더 깊게 생각해서 그런가 보다" 하고 넘겼음. 근데 며칠 디버깅하면서 보니까 모델 문제가 아예 아니었어요.
진짜 범인은 백엔드 쪽이었습니다. 정확히는 MCP 서버가 컨텍스트 윈도우에 정리 안 된 데이터를 자꾸 쏟아부어서, 모델이 매 턴마다 그걸 다시 읽느라 돈이 새고 있던 거예요.
이 글은 Claude Code 같은 에이전트 환경 쓰면서 "왜 이렇게 비싸지?" 싶었던 사람용. 이론보단 어디서 토큰이 새는지 구조적으로 짚어볼게요.

토큰이 도대체 어디로 새는가
세 군데에서 줄줄 새고 있었어요. 하나씩 봅시다.
1) Documentation Dump (문서 통째로 토하기)
Supabase 같은 표준 MCP 서버 써본 사람은 알 거예요. Claude한테 "Google OAuth 설정 좀 도와줘" 하면 서버가 OAuth 부분만 깔끔하게 주는 게 아니라, GraphQL 스키마 메타데이터를 통째로 뱉습니다. SAML, Magic Link, SSO, 전화번호 인증까지 들어 있는 인증 매뉴얼 전체가 컨텍스트에 그대로 박혀요.
이게 매 툴 호출마다 일어남. DB 쿼리 한 번, 스토리지 설정 한 번, 엣지 함수 한 번 — 매번 필요한 양의 5~10배가 따라옵니다. 한 세션에서 수십만 토큰이 그냥 증발.
2) Dashboard Blindness (대시보드를 못 본다)
사람은 백엔드 콘솔 열면 테이블, RLS 정책, 배포된 함수가 한눈에 들어오잖아요. 에이전트는 그걸 못 봐요. 프로그래밍 방식으로 상태를 일일이 캐물어야 합니다.
문제는 표준 MCP에 get_full_topology 같은 단일 엔드포인트가 없다는 것. 그래서 list_tables 한 번, execute_sql 한 번, 스토리지 한 번… 퍼즐 맞추듯 단편적인 호출을 계속 날려요. 이게 다 토큰입니다.
(잠깐 딴 얘긴데, 저 이거 처음 알았을 때 옆자리 동료가 "그래서 GUI라는 게 인간한테 그렇게 효율적이었던 거구나" 하고 지나갔는데 묘하게 인상 깊었어요. 시각적 인터페이스의 정보 압축률이 진짜 미친 거였음)

3) 에러 루프 — 이게 진짜 무서움
이게 조용히 사람 죽이는 부분이에요. 에이전트가 401이나 500 같은 일반 에러를 만나면, 인간처럼 로그 교차검증을 못 합니다. 그냥 추측해서 코드 고치고 재시도해요.
근데 LLM의 잔인한 진실은 — 모든 재시도가 대화 히스토리 전체를 다시 보낸다는 것.
벤치마크 실험에서 나온 사례 하나 보면, 문서 업로드 중에 401 에러가 났는데 에이전트가 8라운드 동안 프론트엔드 코드만 다시 짜고, 함수 재배포하고, 로그 보고… 정작 실제 원인은 코드 실행 전 단계의 보안 게이트가 토큰을 거절한 거였어요. 로그가 어디서 막혔는지 안 알려주니까 8번을 헛다리.
그동안 컨텍스트는 계속 부풀어서, 8번째 시도는 첫 시도보다 몇 배 비쌌습니다. 자기 꼬리 먹는 뱀처럼 비용이 기하급수로 늘어나는 구조.
그래서 어떻게 푸느냐
Andrej Karpathy가 컨텍스트 엔지니어링을 "다음 단계에 필요한 딱 그만큼의 정보로 컨텍스트 윈도우를 채우는 섬세한 기술"이라고 정의했는데요. 우리는 프롬프트에선 이걸 신경 쓰면서 백엔드에서는 완전히 무시하고 있더라고요.
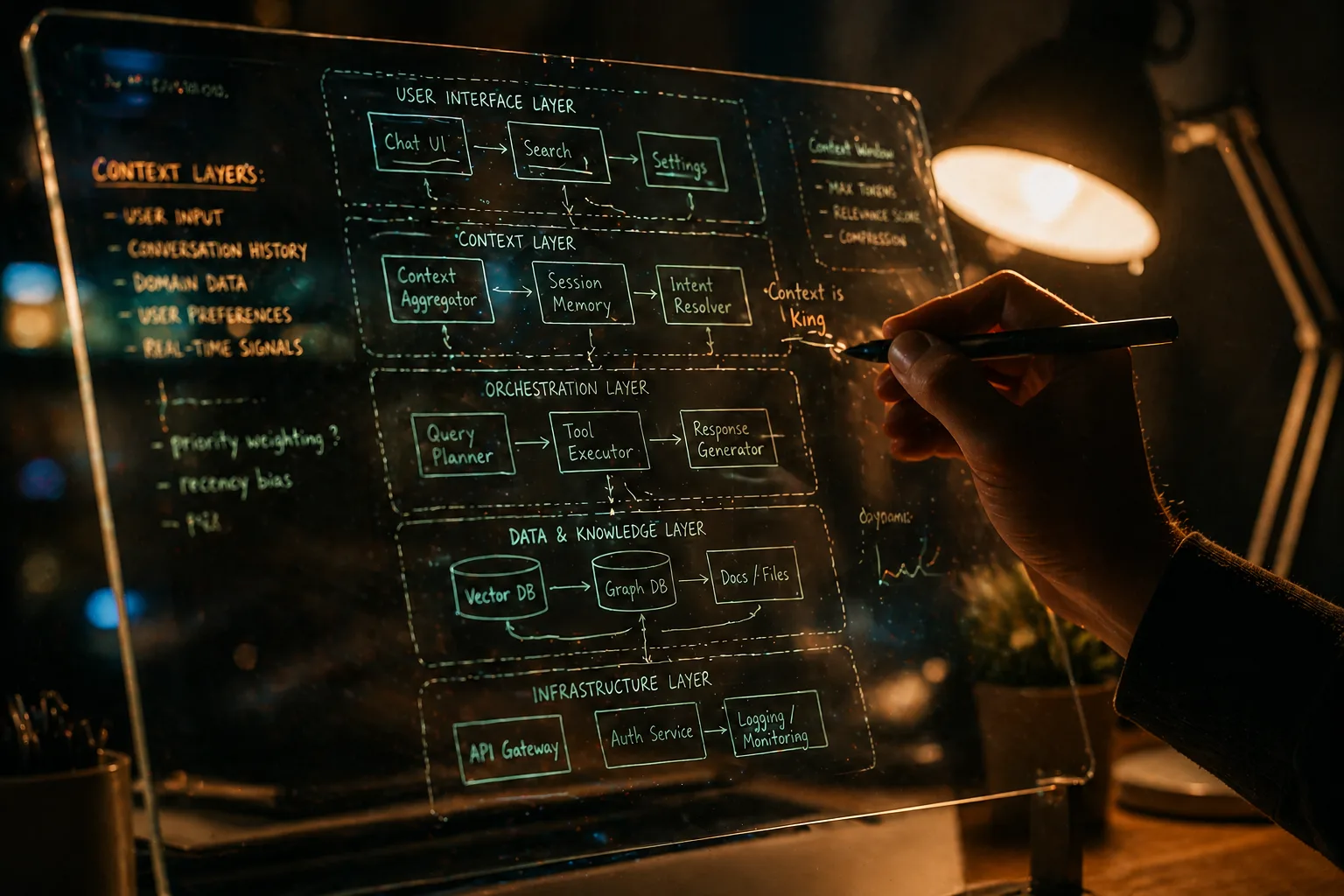
답은 Claude한테 "좀 간결하게 해줘" 하고 잔소리하는 게 아니라, 아키텍처를 다시 짜는 것.
오픈소스 도구 중에 InsForge라고 있어요 (개인적으로 최근에 본 것 중 제일 잘 만든 듯). 컨텍스트를 세 층으로 분리해서 처리합니다.
Skills — 정적 지식
세션 시작할 때 두꺼운 문서를 통째로 던지지 않음. 진짜 필요한 메타데이터만 100토큰 정도로 먼저 로드해요. 에이전트가 "지금 디버깅 중이야" 하고 영역을 명시적으로 확정해야 그때 디테일이 들어옴. 점진적 공개(progressive disclosure) 방식.
CLI — 직접 실행
복잡한 배포를 채팅으로 시키지 말고, 구조화된 JSON 뱉는 로컬 CLI를 쥐어주기. npx @insforge/cli 같은 거 터미널로 돌리면 시맨틱 종료 코드가 나오니까, 에이전트가 천 줄짜리 raw 로그 읽을 필요 없이 깔끔한 JSON으로 "권한 실패" 라고 받습니다. 에러 루프가 여기서 끊겨요.
MCP — 라이브 상태만
MCP는 문서 가져오는 데 쓰지 말고 살아 있는 상태 확인용으로만. get_backend_metadata 한 방으로 테이블/인증/스토리지/모델 토폴로지가 500토큰짜리 JSON으로 한 번에 옴. 디스커버리 세금 0.

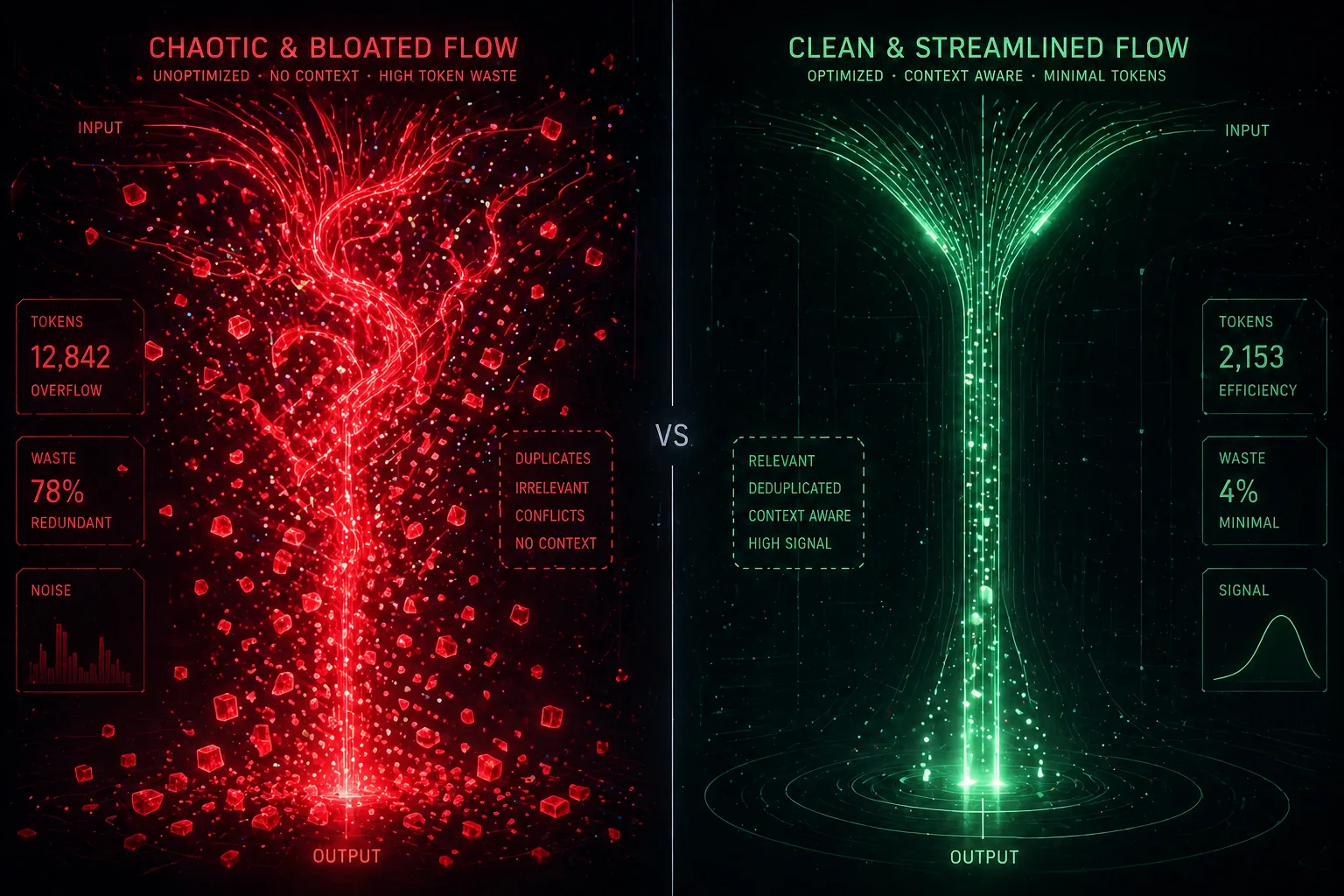
실제 벤치마크 보면 더 와닿음
같은 RAG 앱 만드는 프롬프트로 비교한 결과:
- 표준 Supabase + 일반 MCP: 10.4M 토큰, $9.21, 중간에 사람이 에러 루프 빼줘야 했음
- InsForge 구조: 3.7M 토큰, $2.81, 한 번에 통과
거의 3배 차이. 하루 두세 시간 Claude Code 돌리는 개인 개발자 기준으로도 한 달이면 청구서에서 확연히 보이는 액수입니다.
솔직한 한계
InsForge가 만능은 아니에요. 아직 생태계가 작아서 Supabase처럼 튜토리얼이 풍부하지 않습니다. 저도 처음 세팅할 때 30분쯤 헤맸어요. 문서 검색해도 안 나오는 부분 몇 개 있어서 깃허브 이슈 뒤져야 했고.
그리고 기존 프로젝트를 통째로 옮기는 건 비현실적이에요. 신규 프로젝트나 토큰 진짜 많이 먹는 워크로드만 골라서 옮기는 게 현실적인 선택인 듯. 어쩔 수 없는 부분이고요.
본질적으로 중요한 건 "어떤 도구를 쓰느냐"보다 "컨텍스트 엔지니어링 사고방식이 있느냐" 입니다. InsForge 안 써도 같은 원리로 자기 백엔드 MCP를 직접 깎아서 만들어도 돼요. 도구는 그냥 잘 만들어진 레퍼런스 정도로 보면 됨.
끝맺으며
저는 4.7로 올린 후 한 달은 그냥 비싸게 썼어요. 진작 구조 손볼 걸 그랬다는 후회. 모델 똑똑해질수록 컨텍스트 비용은 더 가팔라질 거고, 6.x 시대 7.x 시대 가면 이 문제가 지금보다 더 심해질 거 같습니다.
AI한테 "내 인프라가 어떻게 생겼는지 알아맞혀봐" 시키면서 돈 내는 거, 솔직히 이제 그만할 때 됐다고 봅니다. 시니어 레벨 자율 엔지니어링을 원하면 시니어 레벨로 정리된 컨텍스트 윈도우를 줘야지, 무지성 덤프해놓고 모델 탓하는 건 너무 무책임한 듯.
댓글
NEXT_PUBLIC_GISCUS_*환경변수 구성 필요)